
Extract advanced Solr features with Drupal

Shankar
Drupal
Published on 22 Jan, 2019
7 min read
Instances of advanced search can be seen through different things. Take space research for instance. In their perpetual effort to explore Universe and search for Earth-like planets or a star that is similar to our Sun, Scientists wind up discovering interesting things. NASA’s Hubble Space Telescope was used to spot a star called Icarus, named after Greek mythological figure, which is the most distant star ever viewed and is located halfway across the universe.

On the other side of the spectrum, Apache Solr is making huge strides with its advanced search capabilities. Enterprise-level search is a quintessential necessity for your online presence to be able to thrive in this digital age. Big organisations like Apple, Bloomberg, Marketo, Roku among others are opting for Apache Solr for its advanced search features. The Amalgamation of Drupal and Apache Solr can be a remarkable solution for a magnificent digital presence.
Planting the seed in 2004
John Thuma, in one of his blog posts, stated that tracing the history of Apache Solr would take us back to the year 2004 when it was an in-house project at CNET Networks used for offering search functionalities for the company’s website. It, then, donated it to the Apache Software Foundation in 2006.
Later, the Apache Lucene and Solr projects combined in 2010 with Solr becoming a sub-project of Lucene. It has witnessed an awful lot of alterations since then and is now a very significant component in the market.
Uncloaking Apache Solr

As an enterprise-capable, open source search platform, Apache Solr is based on the Apache Lucene search library and is one of most widely deployed search platforms in the world.
Solr is a standalone enterprise search server with a REST-like API. You put documents in it (called "indexing") via JSON, XML, CSV or binary over HTTP. You query it via HTTP GET and receive JSON, XML, CSV or binary results. - Lucene.apache.org
It is written in Java and offers both a RESTful XML interface and a JSON API that enables the development of search applications. Its perpetual development by an enormous community of open source committers under the direction of the Apache Software Foundation has been a great boost.
Apache Solr is often debated alongside Elasticsearch. There is even a dedicated website called solr-vs-elasticsearch that compares both of them on various parameters. It states that both the solutions have support for integration with open source content management system like Drupal. It depends upon your organisation’s needs to select from either one of them.
For instance, if your team comprises a plentitude of Java programmers, or you already are using ZooKeeper and Java in your stack, you can opt for Apache Solr. On the contrary, if your team constitutes PHP/Ruby/Python/full stack programmers or you already are using Kibana/ ELK stack (Elasticsearch, Logstash, Kibana) for handling logs, you can choose Elasticsearch.
Characteristics of Apache Solr
Following are the features of Apache Solr:
Advanced search capabilities
- Spectacular matching capabilities: Apache Solr is characterised by the advanced full-text search capabilities. It enables spectacular matching capabilities comprising of phrases, grouping, wildcards, joins and so on, across any data type.
- A wide array of faceting algorithms: It has the support for faceted search and filtering that enables you to slice and dice your data as needed.
- Location-based search: It offers out-of-the-box geospatial search functionalities.
- Multi-tenant architecture: It offers multiple search indices that streamlines the process of segregating content and users.
- Suggestions while querying: There is support for auto-complete while searching (typeahead search), spell checking and many more.
Scalability
It is optimised for the colossal spike in traffic. Also, Solr is built on Apache Zookeeper which makes it easy to scale up or down. It has in-built support for replication, distribution, rebalancing and fault tolerance.
Support for standards-based open interfaces and data formats
It uses the standards-based open interfaces like XML, JSON and HTTP. Furthermore, you do not have to waste time converting all the data to a common representation as Solr supports JSON, CSV, XML and many more out-of-the-box.
Responsive admin UI
It has the provision for an out-of-the-box admin user interface that makes it easier to administer your Solr instances.
Streamlined monitoring
Solr publishes truckload of metric data via JMX that assists you in getting more insights into your instances. Moreover, the logging is monitorable as the log files can be easily accessed from the admin interface.
Magnificent extensions
It has an extensible plugin architecture for making it simple to plugin both index and query time plugins. It also provides optional plugins for indexing rich content, detecting language, clustering search results amongst others.
Configuration management
Its flexibility and adaptability for easy configuration are top-notch. It also offers advanced configurable text analysis, that means, there is support for most of the widely spoken languages in the world and a plethora of analysis tools that makes the process of indexing and querying your content flexible.
Performance optimisation
It has been tuned to govern largest of sites and its out-of-the-box caches have fine-grained controls that assist in optimising performance.
Amazing Indexing capabilities
Solr leverages Lucene’s Near Real-Time Indexing capabilities that ensure that the user sees the content whenever he or she wants to. Also, its built-in Apache Tika simplifies the process of indexing rich content like Microsoft Word, Adobe PDF and many more.
Schema management
You can leverage Solr’s data-driven schemaless mode in the incipient stage of development and can lock it down during the time of production.
Security
Solr has robust built-in security like SSL (Secure Sockets Layer), Authentication and role-based authorisation.
Storage
Lucene’s advanced storage options like codecs, directories among others ensures that you can fine-tune your data storage needs that are applicable for your application.
Leverage Apache UIMA
Enhancement of content can be done with its advanced annotation engines. It incorporates Apache UIMA for leveraging NLP (Natural Language Processing) and other tools for your application.
Integrating Apache Solr with Drupal
Drupal’s impressive flexibility empowers digital innovation and gives the power to the users to build almost anything. It has the provision for integration of your website with Solr platform. Drupal’s Search API Solr Search module provides a Solr backend for the Drupal Search API module.
Drupal’s Search API Solr Search module provides a Solr backend for the Drupal Search API module.
To begin with, you need to have Apache Solr installed on your server. This is followed by the validation of the Solr server’s status using Terminal. It is succeeded by the installation of Search API Solr Search module using Composer.
Once the installation of Search API Solr Search module is done, the process of configuration of Solr ensues. This involves the creation of collection which is basically a logical index linked to a config set.
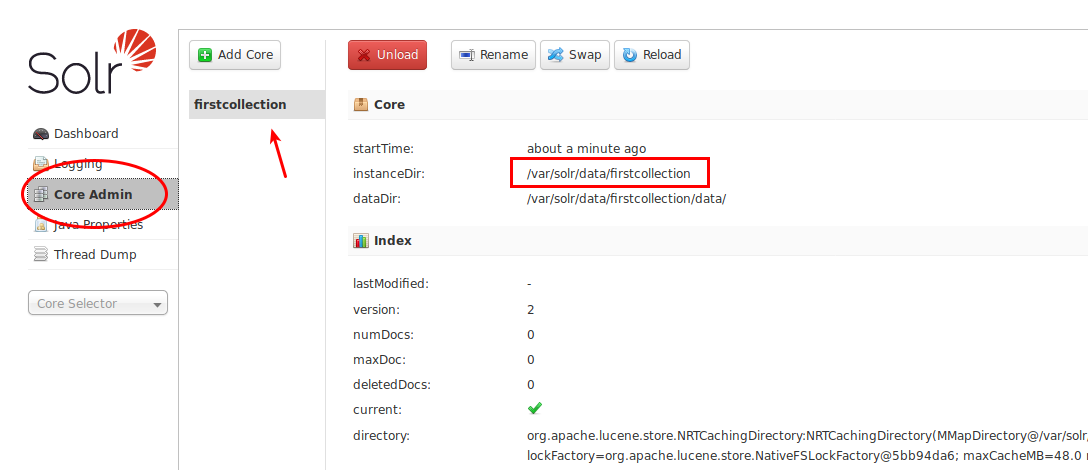
Then, Drupal’s default search module is uninstalled for negating any performance issues and the Search API Solr Search module is enabled. You can, then, move on to the process of configuration of the Search API. Finally, you can test the Search API Solr Search module.
Case study
The Rainforest Alliance (RA), which is an international non-profit organisation working towards the development of strong forests, healthy agricultural work landscapes, and burgeoning communities via creative collaboration, leveraged the power of Drupal to revamp their website with the help of a digital agency.
RA has built a repository of structured content for supporting its mission and the content is primarily exhibited as long-form text with a huge variety of metadata and assets associated with each part of the content. It wanted to revamp the site and enable the discovery of new content on the site with the help of the automatic selection of related content. It also required the advanced permission features and publishing workflows.
Drupal was great because of its deep integrations with Apache Solr that enabled nuanced content relation engine.
Drupal turned out to be an astounding choice for fulfilling RA’s requirement of portable and searchable content. It was also great because of its deep integrations with Apache Solr that enabled nuanced content relation engine. Solr was leveraged for powering various search interfaces. Furthermore, Drupal’s wonderful content workflow features made it a perfect choice.
Solr offered ‘more like this’ (MLT) functionality that was more robust than just tagging content and showing other content with the same taxonomy terms. Search API Solr Search module, which provides a Solr backend for the Search API module, was utilised for providing the interface to govern the servers and indexes. Then, with a custom block, MLT was leveraged for assisting the process generating related content lists.
Page manager module, in combination with Layout Plugin and Panels modules, was used to build specialised landing pages in the form of specialised page manager pages with many of them having their own layouts. Different modules were utilised from within the media ecosystem of Drupal were very beneficial in administering images, embedding videos, and so on. Entity Embed, Entity Browser and Inline Entity form were magnificent for a great editorial experience for content teams.
Conclusion
Apache Solr is a great solution for enabling enterprise-level search and can make a world of difference in combination with Drupal for your digital presence.
We have been empowering our partners in their efforts digital transformation dreams with our expertise in Drupal development.
Ping us at [email protected] to extract advanced Solr features with Drupal.
Subscribe
Related Blogs
What is HTMX & How it Works for Server-Driven Web Interfaces?

“HTML was designed to explain user interactions. HTMX pushes that behavior back where it started, the markup itself." This…
DrupalCon Chicago: Key Product & AI Updates

“The DrupalCon Chicago keynote looks back at Drupal’s 25-year journey while outlining how the platform is evolving. It…
DrupalCamp Delhi Returns After 6 Years: Here’s What to Expect

“After the COVID period, this marks the first time the camp is returning to Delhi. Over the years, the camp and the local…