
Comparing web services implementations: REST vs JSON:API vs GraphQL

Gurpreet Kaur
Technology
Published on 20 Jan, 2021
16 min read
People today do not like to be confined, if I talk about development teams, they would hold up flags stating the same. Since development and innovation go hand in hand and constraint is the biggest enemy of innovation, you can’t tell me they are wrong to have that notion.
Talking specifically about web developments, there are a lot of areas to explore and a lot of technologies to help you do that. So, why limit yourself, when you don't have to? Drupal has brought such an impressive trend forward that has simply satiated the developer’s desire for innovation and that is the headless approach.
Unlike before, when your entire project had to be nestled inside one CMS, Drupal now gives you the opportunity to explore new technologies to your heart’s desire. This is possible because the presentation layer and the backend content become two separate entities. Drupal acts as the content repository and a frontend technology of your liking takes care of, of course, the frontend part of website architecture.
To provide a connection between the separated development aspects of the project, enters the API. An API layer is a necessity when going headless, because it transmits all the information from the front to the backend and vice-versa.
And the three available APIs in Drupal, REST, JSON and GraphQL, are the reason behind me writing this blog. Although the purpose of all three is the same, they are quite different from one another. Today, we would be highlighting their meanings, their pros and cons and all the visible distinctions they have. So, let’s begin.
Decoding the APIs

REST, JSON and GraphQL bring in a similar outcome when they are used for decoupling Drupal. Yes, they are different too. And we would get into the difference between REST, JSON and GraphQL soon. Before that it is essential to understand their history, origin and what they were intended for because the differences actually start from there.
REST
REST was developed by Roy Fielding in the year 2000, the purpose behind its development was to provide a software architectural design for APIs. In simple terms, it provided an easy path for one computer to interact with another by utilising an HTTP protocol. The communication between the two computers is not stored on the server, meaning it is stateless; rather the client sessions are stored on a client-side server.
There are six constraints necessary to implement REST in the complete sense.
- It needs a separated client and server;
- It needs to be able to make independent calls;
- It needs to able to store cacheable data;
- It needs to have a uniform interface;
- It is a layered system;
- Finally, it needs a code-on-demand.
REST offers a great deal of functionality without a lot of effort. For instance, if you are working on someone else’s RESTful API, you would not need a special library or special initialisation. Yes, your developers need to design their own data model using REST, but the HTTP conventions at play make programming a breeze.
To know how REST plays a key role in decoupling Drupal, read our blog REST APIs in Drupal.
JSON: API
JSON stands for JavaScript Object Notation. Built in May of 2013, it was designed as an encoding scheme, eliminating the need for ad-hoc code for every application to communicate with servers, which use a defined way for the same. JSON: API, like the name says, is a specification for building APIs using JSON.
With JSON: API, communication between the server and the client becomes extremely convenient. It not only formats the way a request should be written, but the responses also come in a formatted manner. The primary aim of JSON: API is to lessen the number of requests and shrink the size of the package, all using HTTP protocol.
Broadly stated;
- JSON reduces the number of requests and amount of data being transmitted;
- It requires zero configuration;
- It uses the same JSON access scheme for every piece of data, making caching very effective;
- It offers quite a few features and gives you, as the client, the opportunity to turn them on or off.
To know how JSON:API plays a key role in decoupling Drupal, read our blog, JSON API in Drupal.
GraphQL
While JSON can work alongside REST, GraphQL was designed as an alternate to it and some of its inconveniences. Built in 2012 by Facebook, it acts as a cross-platform data query and manipulation language. Its servers are available in numerous popular languages, being Java, JavaScript, Ruby, Python, C#, amongst others.
The features of GraphQL are that;
- It allows users to request data from multiple resources in a single request.
- It can be used to make ad-hoc queries to one endpoint and access all the needed data.
- It gives the client the opportunity to specify the exact type of data needed from the server.
- All of these add to its predictable data structure, making it readable as well as efficient.
It was in 2015, after GraphQL was open-sourced that it became truly popular. Now its development is governed by The GraphQL Foundation, which is hosted by the Linux Foundation.
To know how GraphQL plays a key role in decoupling Drupal, read our blog, GraphQL in Drupal.
Now that we know the basics of all the three APIs, let us have a look at their popularity status, before beginning the comparison.
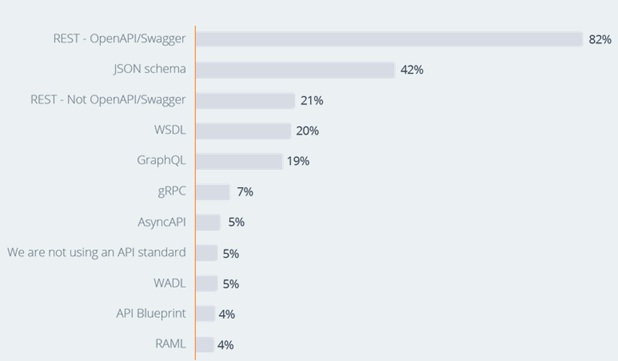
REST vs JSON vs GraphQL
Now let’s get down to the details and understand why choosing one over the other two could be in your best interest. Let’s start with the differences between REST, JSON:API and GraphQL.
How efficient is the data retrieval?

One of the most important aspects for an API is the way its fetches data. It could require one or more requests. Therefore, this aspect is also referred to as its request efficiency. Getting multiple data responses in a single request has to be an ideal, so let’s see how REST, JSON: API and GraphQL here.
REST
The REST API is innately built to capitalise one resource per request. This works perfectly as long as you only need to retrieve a single piece of data like an article. However, if you need more than that, the number of requests you would have to type in separately would be equivalent to the amount of data you need.
One article = one request
Two articles = two requests
Two articles and the author information stored in a different field = Two requests for the articles + a long wait for the completion of those requests + two additional requests for the author information.
This sums up REST’s request efficiency to the T. You require to be equipped to handle a number of requests, which can ultimately stall your user experience, making it seem to go at a snail’s pace. No sugar-coating here, there are going to be a lot of round trips.
And the problem with a lot of round trips is a lot of extra information you do not even need. This is because there is a possibility that a REST API endpoint might not have the required data for an application. As a result, the said application will not get everything it needs in a single trip, making multiple trips the only option. It's safe to say that REST over-fetches and the verbose responses can be a problem.
JSON: API
JSON: API does not suffer from the multiple request conundrum. One single request can give you everything you want, be it one article, two or ten along with the author’s information, I kid you not.
This is possible because JSON: API implements a concept called ‘sparse fields.’ What this does is list the desired resource fields together for easy fetching. You can have as many fields as possible. If you feel the fields are too long and would not be cacheable, you can simply omit a few sparse fieldsets to cache the request.
Another thing to remember is that the servers can choose sensible defaults, so your developers would need to be a little diligent to avoid over-fetching.
GraphQL
Coming to GraphQL, it was also designed in a similar fashion to JSON: API and is competent enough to eliminate the problem of over-fetching and avoid sending multiple requests.
GraphQL has its own queries, schema and resolvers that aid the developers in creating API calls with particular data requirements in mind. Moreover, by mandating clear-cut additions to every resource field in every query and ensuring the developers cannot skip any of it, it is able to avoid multiple round trips. Thereby, making over-fetching information a thing of the past.
The only problem here can be that the queries may become too large, and consequently, cannot be cached.
How is the code executed?

Using an API for calls involves the execution of a code on the server. This code helps in computing, calling another API or loading data from a database. All three of the APIs use a code, however, the code is implemented varies a little.
REST
Route handlers are utilised for execution upon a REST call. These are basically functions for specific URLs.
- First the server receives the call and retrieves the URL path and GET;
- Then the functions are noted and the servers begins finding the same by matching GET and the path;
- After that the result is generated, since the server would have executed the function;
- In the final step, once the result is serialised by the API library, it is ready for the client to see.
GraphQL
GraphQL operates in a relatively similar manner. The only difference is that it uses functions for a field within a type, like a Query type, instead of using functions for specific URLs.
Route handlers are replaced by resolvers in GraphQL, they are still functions though.
- After the call is made and the server has received a request, the GraphQL query is retrieved.
- The query is then examined and the resolver is called upon for every field.
- Finally, the result is added to the response by the GraphQL library and it is ready for the client to see.
It should be noted that GraphQL offers much more flexibility as multiple fields can be requested in one request, and the same field can be called multiple times in one query. The fact they let you know where you performance needs fine-tuning makes resolvers excellent trackers as well.
This is simply not possible in REST and JSON. Do you see the difference in implementation?
How do the API endpoints play a role?
Many a time, it is seen that once the API is designed and the endpoints are sealed, the applications require frontend iterations that cannot be avoided. You must know that the endpoints aid an application to receive the required data just by accessing it quickly in the view, so you could call them essential even.
However, the endpoints can pose a bit of a problem for the iterations, especially when they need to be quick. Since, in such an instance, changes in the API endpoints have to be made for every change in the frontend, the backend gets tedious for no reason at all. The data required for the same can be on the heavier side or the lighter side, which ultimately hampers the productivity.
So, which API offers the solution?
It is neither REST, nor JSON. GraphQL’s flexibility makes it easy for the developers to write queries mentioning the specific data needs along with iterations for the development of the frontend, without the backend having to bear the brunt.
Moreover, GraphQL’s queries help developers on retrieving specific data elements and provide insights to the user as to which elements are popular and which aren’t amongst the clients.
Why doesn’t REST?
The answer is simple, REST has the entire data in a single API endpoint. Being a user, you won’t be able to gain insights on the use of specific data as the whole of it always returned.
How good is the API exploration?

Understanding your API and knowing about all of its resources and that too quickly and with ease is always going to benefit your developers. In this aspect, all three perform pretty contrastingly.
REST
REST gives a lacklustre performance in API exploration to be honest. The interactivity is pretty substandard as the navigation links are seldom available.
In terms of the schema, it would only be programmable and validatable, if you are going to be using the OpenAPI standard. The auto-generation of the documentation also depends on the same.
JSON: API
JSON performs better than REST. The observation of the available field and links in JSON: API’s responses helps in its exploration and makes its interactivity quite good. You can explore it using a web browser, cURL or Postman.
Browsing from one resource to the next, debugging or even trying to develop on top of an HTTP-based API, like REST, can be done through a web browser alongside JSON.
GraphQL
GraphQL is indeed the front-runner here. It has an impressive feature, known as the GraphiQL, due to which its API exploration is unparalleled. It is an in-browser IDE, which allows the developers to create queries repeatedly.
What is even more impressive is the fact the queries get auto-completed based on the suggestions it provides and you get real-time results.
Let’s focus on schema now

Schemas are important for the development team, the frontend and the backend equally. It is because once a schema has been defined, your team would know the data structure and can work in parallel. Creating dummy test data as well as testing the application would be easy for the frontend developers. All in all, the productivity and efficiency levels elevate.
REST
REST does have an associated expected resource schema since it is a set of standard verbiage. Despite this, there is nothing that is specifically stated in them.
JSON: API
In terms of schema validation and programming, it does define a generic one, however, a reliable field-level schema is yet to be seen. Simply put, JSON is basic with regards to schema.
GraphQL
The fact that GraphQL functions completely on schemas makes it a pro in this regard. The schema used here is Schema Definition Language or SDL. What this means is that GraphQL uses a type system that sets out the types in an API because all the types are included in SDL. Thus, defining the way a client should access data on the server becomes easy.
To conclude this point, I would want to say that when there is immense complexity in the schema and resource relationships, it can pose a disadvantage for the API.
How simple is to operate it?

Operating an API essentially involves everything, from installing and configuring it to scaling and making it secure. REST, JSON: API and GraphQL, all perform well enough to make themselves easy to operate. Let’s see how.
REST
REST is quite simple to use, a walk in the park for a pro developer. It is because REST is dependent on the conventional HTTP verbiage and techniques. You would not need to transform the underlying resources by much, since it can be supported by almost anything. It also has a lot of tools available for the developers, however, these are dependent on their customisation before they can be implemented.
In terms of scaling, REST is extremely scalable, handling high traffic websites is no problem at all. To take advantage of the same, you can make use of a reverse proxy like Varnish or CDN. Another plus point of REST is that it has limited points of failure, being the server and the client.
JSON: API
JSON: API is more or less the same as REST in terms of its operational simplicity, so much so that you can move from REST to JSON: API without any extensive costs.
- It also relies on HTTP;
- It is also extremely scalable;
- It also has numerous developer tools, but unlike REST, JSON: API does not need customised implementations;
- Lastly, JSON also has fewer failure points.
GraphQL
GraphQL is the odd one out here. It isn’t as simple to use as the other two. It necessitates specific relational structure and specific mechanisms for interlocking. You would be thinkin that how is this complex? Let me ask you to focus on word specific, what this means is that you might need to restructure your entire API with regards to resource logic. And you must know that such restructuring would cost you time, money and a boatload of efforts.
Even in terms of scalability, GraphQL does not fare very well. The most basic requests also tend to use GET requests. For you to truly capitalise GraphQL, your servers would need their own tooling. If I talk about the points of failure here, even those are many, including client, server, client-side caching and client and build tooling.
What about being secure?

The kind of security an API offers is also an important consideration in choosing it. A drastic difference is noted in REST and GraphQL. Let’s see what that is.
REST
REST is the most secure amongst the three. The intrinsic security features in REST are the reason for the achievement.
- There are different APU authentication methods, inclusive of HTTP authentication;
- There are the JSON Web Tokens for sensitive data in HTTP headers;
- There are also the standard OAuth 2.0 mechanisms for sensitive data in JSON structure.
JSON:API
JSON:API is on a similar footing to REST in terms of security. The reason being the fact that like REST it exposes little resources.
GraphQL
It is not like GraphQL is not secure, it is; however, the security has to be manually attained. It is not secure by default and it is not as mature as REST in this regard.
When the user has to apply authentication and authorisation measures on top of data validation, the chances of unpredictable authorisation checks rise. Now, do I have to tell you that such an event is bound to jeopardise your security?
How is the API design pinpointed?
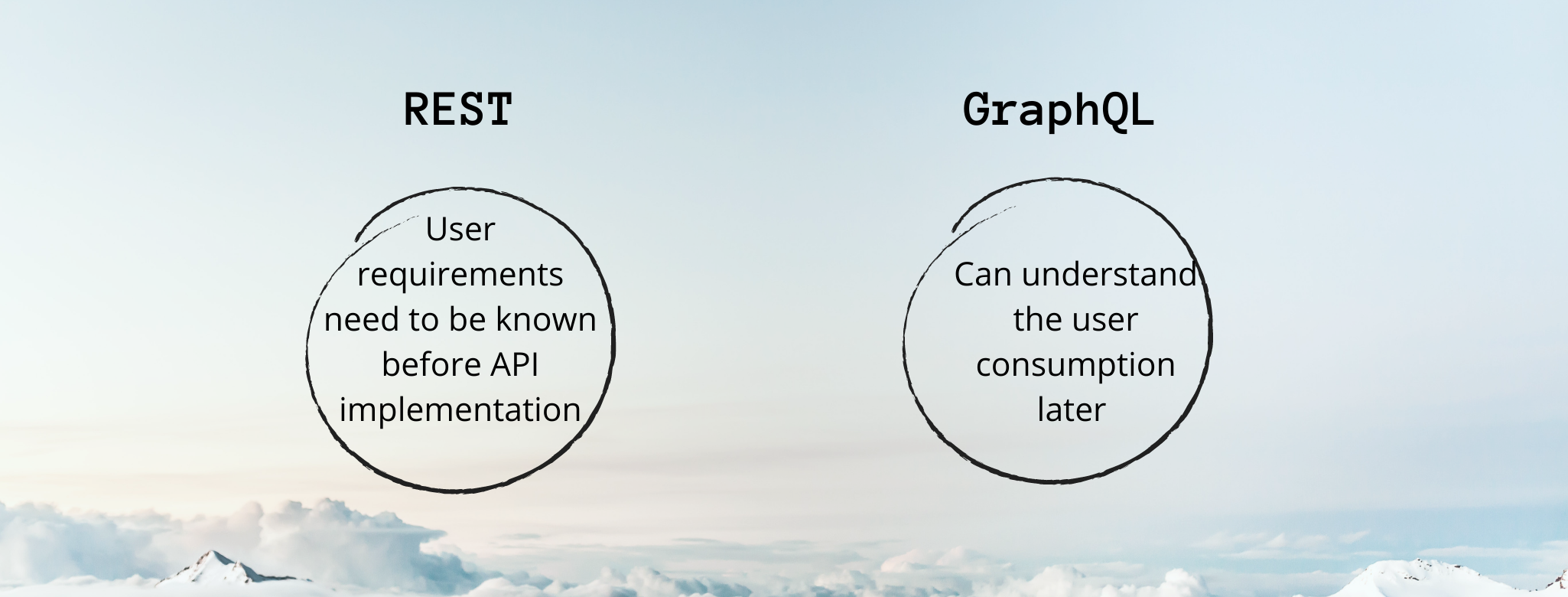
If an API has to perform well for every use case, you have to make it do so. By creating such design choices that are a result of your understanding of the users’ needs. You cannot just go with the flow, evaluating how your users are going to be interacting with your API and getting an understanding of the same is key for your API’s design.
REST
For REST, this exercise of deciphering the user requirements must happen before the API can be implemented.
GraphQL
As for GraphQL, this apprehension can be delayed a little. By profiling the queries, you would be able to tell their complexity level and pinpoint the sluggish queries to get to an understanding of user’s consumption of the API.
What about their use in Drupal?

Drupal is an important player when it comes to building websites and managing their content. With decoupling Drupal becoming more and more popular, it has become crucial to understand how the APIs perform alongside Drupal.
REST
Talking about the installation and configuration of REST, it can be complicated at best. The fact that the REST module has to be accompanied by the REST UI module does not ease the complexity.
With REST, the clients that cannot create queries with the needed filters on their own, since the REST module does not support client-generated collection queries. This is often referred to as decoupled filtering.
JSON:API
JSON:API module landed in Drupal core in Drupal 8.7. JSON:API’s configuration is as easy as ABC, there is simply nothing to configure. JSON is a clear winner in this aspect.
Moving to client-generated queries, JSON does offer its clients this luxury. They can generate their own content queries and they won't need a server-side configuration for the same. JSON’s ability to manage access control mechanisms offered by Drupal make changing an incoming query easy. This is a default feature in JSON:API.
GraphQL
The installation of GraphQL is also not as complicated as REST, but it isn’t as easy as JSON as well. This is because it does mandate some level of configuration from you.
Similar to JSON, GraphQL also offers decoupled filtering with client generated queries. A less common trend amongst GraphQL projects is seeking permissions for persisted queries over client-generated queries; entailing a return to the conventional Views-like pattern.
In addition to these three major Drupal web services, explore other alternatives in the decoupled Drupal ecosystem worthy of a trial. Read everything about decoupled Drupal, the architecture-level differences between headless and traditional setups, different ways to decouple Drupal, and the skills required to build a Decoupled Drupal web application to know more.
Concluding with the basics
To sum up, let us look at the fundamental nature of the three APIs, which entails two aspects; simplicity and functionality.
In terms of simplicity, REST is a winner. A second would be rewarded to JSON, while GraphQL would not and could not be described as simple, complex and that too immensely with major implementations coming your way would be a more accurate description. In terms of functionality, GraphQL does offer the most. If you choose JSON over GraphQL, you would end up parting with some of its features unfound in JSON.
All three are powerful and efficient in what they can do for your application. The question is how much complexity are you willing to take up with that power?
Subscribe
Related Blogs
AI Fairness: A Deep Dive Into Microsoft's Fairlearn Toolkit

Artificial intelligence (AI) has changed the game across industries, especially in financial services. From automating…
API Documentation Tool: 10 Best Tools For 2025
A Google search for ‘Best API Documentation Tool’ will show many results. The growing number of API documentation tools…
Debunking 6 Common Software Testing Myths

A flawless product delivery requires a perfect combination of both development and testing efforts. Testing plays a vital…