
Entity Extraction Using NLP in Python

Manish
Technology
Published on 27 Mar, 2018
7 min read
In general, an entity is an existing or real thing like a person, places, organization, or time, etc. By extraction these type of entities we can analyze the effectiveness of the article or can also find the relationship between these entities. This comes under the area of Information Retrieval.
When combined with Drupal the information can be evenly organized. The additional semantic entities in Drupal can be used to ease the process.
These entities are nothing but a noun or noun phrase. A simplified form of this is commonly taught in school and identified as nouns, verbs, adjectives, adverbs, etc.
What Is The Need To Entity Extraction?
Let’s say, you have a task to find the relationship between a company and the location where it is, or relationship between the date of birth and a person.
By extracting the entity type - company, location, person name, date, etc, we can find the relation between the location and the company. With entity extraction, we can also analyze the sentiment of the entity in the whole document.
Create Your Own Entity Extractor In Python
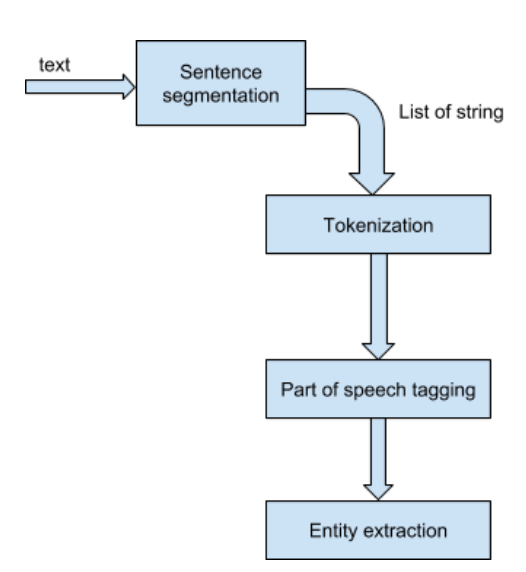
Sentence Segmentation: in this first step text is divided into the list of sentences.
Following is the simple code stub to split the text into the list of string in Python:
>>>import nltk.tokenize as nt
>>>import nltk
>>>text="Being more Pythonic is good for health."
>>>ss=nt.sent_tokenize(text)
Tokenization: Tokenization is the process of splitting the sentences into even smaller parts called 'tokens'.
Following is the simple code stub to tokenize the sentence in Python:
>>> import nltk.tokenize as nt
>>> import nltk
>>> text="Being more Pythonic is good for health."
>>>ss=nt.sent_tokenize(text)
>>>tokenized_sent=[nt.word_tokenize(sent) for sent in ss]
POS Tagging: 'Part of Speech' tagging is the most complex task in entity extraction. The idea is to match the tokens with the corresponding tags (nouns, verbs, adjectives, adverbs, etc.). The process of classifying words into their parts of speech and labeling them accordingly is known as part-of-speech tagging, POS-tagging, or simply tagging. Parts of speech are also known as word classes or lexical categories.
Here is the definition from Wikipedia:
"In corpus linguistics, part-of-speech tagging (POS tagging or POST), also called grammatical tagging or word-category disambiguation, is the process of marking up a word in a text (corpus) as corresponding to a particular part of speech, based on both its definition, as well as its context—i.e. relationship with adjacent and related words in a phrase, sentence, or paragraph.
...POS tagging is now done in the context of computational linguistics, using algorithms which associate discrete terms, as well as hidden parts of speech, in accordance with a set of descriptive tags. POS-tagging algorithms fall into two distinctive groups: rule-based and stochastic."Following is the simple code stub to POS the Tokens in Python:
>>> import nltk.tokenize as nt
>>> import nltk
>>> text="Being more Pythonic is good for health."
>>> ss=nt.sent_tokenize(text)
>>> tokenized_sent=[nt.word_tokenize(sent) for sent in ss]
>>> pos_sentences=[nltk.pos_tag(sent) for sent in tokenized_sent]
>>> pos_sentences
[[('Being', 'VBG'), ('more', 'JJR'), ('Pythonic', 'NNP'), ('is', 'VBZ'), ('good', 'JJ'), ('for', 'IN'), ('health', 'NN'), ('.', '.')]]
The collection of tags used for a particular task is known as a tag set.
Use Case With Drupal
For the various problems related to content publishing (primarily in Media and Publishing vertical) can be overcome with the fusion of NLP and Drupal.
Related Content and Auto Tagging: This is perhaps one of the most important features of any publishing website. ‘Related content’ keeps the user glued for ‘more’ on the website. Presently agencies use tags and categories, which are manually decided and updated. A lot of time is, thus, wasted in tagging, and adding data manually which might result in inefficient use of human resources.
Computing tf-idf score of all the words and use the ones with the highest score as tags can be used. Implementation of NLP helps in entity extraction of entire content and fetch important words. They can be used as tags for related content.
Here is the full POS tag list:
| CC | coordinating conjunction |
| CD | cardinal digit |
| DT | determiner |
| EX | existential there (like: "there is" ... think of it like "there exists") |
| FW | foreign word |
| IN | preposition/subordinating conjunction |
| JJ | adjective 'big' |
| JJR | adjective, comparative 'bigger' |
| JJS | adjective, superlative 'biggest' |
| LS | List marker 1) |
| MD | modal could, will |
| NN | noun, singular 'desk' |
| NNS | noun plural 'desks' |
| NNP | proper noun, singular 'Harrison' |
| NNPS | proper noun, plural 'Americans' |
| PDT | predeterminer 'all the kids' |
| POS | possessive ending parent's |
| PRP | personal pronoun I, he, she |
| PRP$ | possessive pronoun my, his, hers |
| RB | adverb very, silently, |
| RBR | adverb, comparative better |
| RBS | Adverb, superlative best |
| RP | particle give up |
| TO | to go 'to' the store. |
| UH | interjection errrrrrrrm |
| VB | Verb, base form take |
| VBD | verb, past tense, took |
| VBG | Verb, gerund/present participle taking |
| VBN | verb, past participle taken |
| VBP | verb, sing. present, non-3d take |
| VBZ | verb, 3rd person sing. present takes |
| WDT | wh-determiner which |
| WP | wh-pronoun who, what |
| WP$ | possessive wh-pronoun whose |
| WRB | wh-adverb where, when |
Chunking: Also called shallow parsing, with chunking one can identify parts of speech and shorter phrases (like noun phrases). Chunking groups here implies that the token will be broken down into larger tokens or unit.
To create a chunk we first have to write the grammar with the regular expression and tag pattern (is a POS tag enclosed in angle brackets) and then create chunk parser.
The Parser returns a nltk.tree object labeled with the NP(our chunk pattern), which we have to traverse to get the entity out of the tree.
Following code stub extract the Entity from a sentence:
>>> def extract_NN(sent):
grammar = r"""
NBAR:
# Nouns and Adjectives, terminated with Nouns
{<NN.*>*<NN.*>}
NP:
{<NBAR>}
# Above, connected with in/of/etc...
{<NBAR><IN><NBAR>}
"""
chunker = nltk.RegexpParser(grammar)
ne = set()
chunk = chunker.parse(nltk.pos_tag(nltk.word_tokenize(sent)))
for tree in chunk.subtrees(filter=lambda t: t.label() == 'NP'):
ne.add(' '.join([child[0] for child in tree.leaves()]))
return ne
>>> extract_NN(text)
{'health', 'Pythonic'}
While Content Tagging is one of the use cases discussed above, there are related problems, like Categorization, Summarization, SEO mostly related with how human inefficiency, which can be overcome with the implementation.
Summarization: Used for teaser modes, Facebook post or description, Twitter card. Currently summary is either manually written or the system picks up starting paragraphs of the article making it highly susceptible to inefficiency. With auto summarizer, the machine can easily analyze and write the summary from the passage keeping in mind the keywords, sentiments, and the gist of the content.
There are various algorithms to prepare the summary for a given content, they can be classified into abstractive and extractive. By using the gensim library of python, the summary can be obtained and used in various places.
SEO: Similarly, NLP algorithms and libraries can be used to generate meta description, abstraction, keywords, and also microdata which can be used to map content with schema.org specifications.
Sentiment Analysis: Examining the content (texts, images, and videos) and identifying the emotional outlook within the content. The program can identify and classify the writer's attitude as positive, negative, or neutral. This is helpful for media publishing websites which need to balance the emotional outlook of the website overall.
We can clearly see that the extracted entities are `Health` and `Pythonic` which was tagged as NN(noun) and NNP(proper noun)
Here goes the summary
- Named Entity Recognition is a form of chunking.
- Nltk default pos_tag uses PennTreebank tagset to tag the tokens. Check this out to see the full meaning of POS tagset. You can explore more here
- Here I have shown the example of regex-based chunking but nltk provider more chunker which is trained or can be trained to chunk the tokens.
- We can also find the type of entity using NLTK but it is not accurate.
OpenSense Labs developed a module 'intelligent content tools' to personalize the content providing three core functionalities:
- Auto-tagging
- Summarization
- Check duplicate content
Appropriate solutions for your organizational purposes can be found and we would love to hear your requirements at [email protected]
(The project is not covered by security advisory policy please use it at your own risk.)
Contact us at [email protected] for more!
Subscribe
Related Blogs
AI Fairness: A Deep Dive Into Microsoft's Fairlearn Toolkit

Artificial intelligence (AI) has changed the game across industries, especially in financial services. From automating…
API Documentation Tool: 10 Best Tools For 2025
A Google search for ‘Best API Documentation Tool’ will show many results. The growing number of API documentation tools…
Debunking 6 Common Software Testing Myths

A flawless product delivery requires a perfect combination of both development and testing efforts. Testing plays a vital…