Entitätsextraktion mit NLP in Python
Im Allgemeinen ist eine Entität ein existierendes oder reales Ding wie eine Person, ein Ort, eine Organisation oder eine Zeit usw. Durch die Extraktion dieser Art von Entitäten können wir die Effektivität des Artikels analysieren oder auch die Beziehung zwischen diesen Entitäten finden. Dies fällt unter den Bereich der Information Retrieval (Informationsbeschaffung).
In Kombination mit Drupal können die Informationen gleichmäßig organisiert werden. Die zusätzlichen semantischen Entitäten in Drupal können verwendet werden, um den Prozess zu vereinfachen.
Diese Entitäten sind nichts anderes als ein Nomen oder eine Nominalphrase. Eine vereinfachte Form davon wird üblicherweise in der Schule gelehrt und als Nomen, Verben, Adjektive, Adverbien usw. identifiziert.
Warum ist die Entitätsextraktion notwendig?
Nehmen wir an, Sie haben die Aufgabe, die Beziehung zwischen einem Unternehmen und dem Standort, an dem es sich befindet, oder die Beziehung zwischen dem Geburtsdatum und einer Person zu finden.
Durch die Extraktion des Entitätstyps – Unternehmen, Standort, Personenname, Datum usw. – können wir die Beziehung zwischen dem Standort und dem Unternehmen finden. Mit der Entitätsextraktion können wir auch die Stimmung der Entität im gesamten Dokument analysieren.
Erstellen Sie Ihren eigenen Entity Extractor in Python
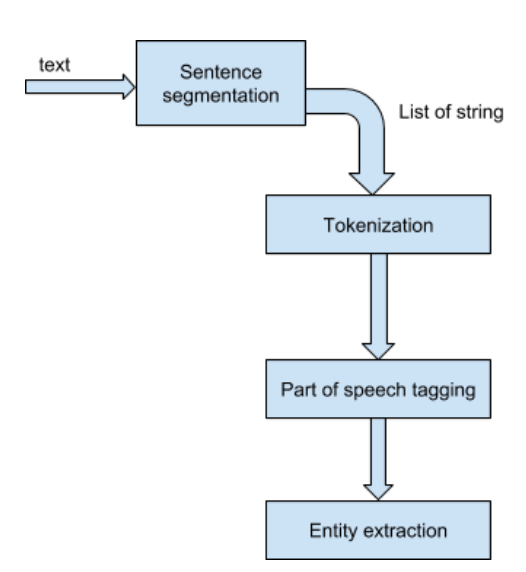
Satzsegmentierung: In diesem ersten Schritt wird der Text in eine Liste von Sätzen unterteilt.
Im Folgenden finden Sie den einfachen Code-Stub, um den Text in Python in die Liste der Zeichenketten aufzuteilen:
>>>import nltk.tokenize as nt
>>>import nltk
>>>text="Being more Pythonic is good for health."
>>>ss=nt.sent_tokenize(text)
Tokenisierung: Tokenisierung ist der Prozess, bei dem die Sätze in noch kleinere Teile, sogenannte 'Tokens', aufgeteilt werden.
Im Folgenden finden Sie den einfachen Code-Stub, um den Satz in Python zu tokenisieren:
>>> import nltk.tokenize as nt
>>> import nltk
>>> text="Being more Pythonic is good for health."
>>>ss=nt.sent_tokenize(text)
>>>tokenized_sent=[nt.word_tokenize(sent) for sent in ss]
POS-Tagging: 'Part of Speech' (Wortart)-Tagging ist die komplexeste Aufgabe bei der Entitätsextraktion. Die Idee ist, die Tokens mit den entsprechenden Tags (Nomen, Verben, Adjektive, Adverbien usw.) abzugleichen. Der Prozess der Klassifizierung von Wörtern in ihre Wortarten und deren entsprechende Kennzeichnung wird als Part-of-Speech-Tagging, POS-Tagging oder einfach Tagging bezeichnet. Wortarten werden auch als Wortklassen oder lexikalische Kategorien bezeichnet.
Hier ist die Definition von Wikipedia:
"In der Korpuslinguistik ist das Part-of-Speech-Tagging (POS-Tagging oder POST), auch grammatikalisches Tagging oder Wortkategorien-Disambiguierung genannt, der Prozess, bei dem ein Wort in einem Text (Korpus) als zu einer bestimmten Wortart gehörig gekennzeichnet wird, basierend sowohl auf seiner Definition als auch auf seinem Kontext – d. h. seiner Beziehung zu benachbarten und verwandten Wörtern in einer Phrase, einem Satz oder einem Absatz.
...POS-Tagging wird heute im Kontext der Computerlinguistik durchgeführt, wobei Algorithmen verwendet werden, die diskrete Begriffe sowie verborgene Wortarten in Übereinstimmung mit einer Reihe von beschreibenden Tags zuordnen. POS-Tagging-Algorithmen lassen sich in zwei unterschiedliche Gruppen einteilen: regelbasiert und stochastisch."Im Folgenden finden Sie den einfachen Code-Stub, um die Tokens in Python mit POS zu versehen:
>>> import nltk.tokenize as nt
>>> import nltk
>>> text="Being more Pythonic is good for health."
>>> ss=nt.sent_tokenize(text)
>>> tokenized_sent=[nt.word_tokenize(sent) for sent in ss]
>>> pos_sentences=[nltk.pos_tag(sent) for sent in tokenized_sent]
>>> pos_sentences
[[('Being', 'VBG'), ('more', 'JJR'), ('Pythonic', 'NNP'), ('is', 'VBZ'), ('good', 'JJ'), ('for', 'IN'), ('health', 'NN'), ('.', '.')]]
Die Sammlung von Tags, die für eine bestimmte Aufgabe verwendet werden, wird als Tag-Set bezeichnet.
Anwendungsfall mit Drupal
Die verschiedenen Probleme im Zusammenhang mit der Inhaltsveröffentlichung (hauptsächlich im Bereich Medien und Verlagswesen) können durch die Verschmelzung von NLP und Drupal gelöst werden.
Verwandte Inhalte und Auto-Tagging: Dies ist vielleicht eine der wichtigsten Funktionen jeder Verlagswebsite. "Verwandte Inhalte" halten den Benutzer auf der Website für "mehr" fest. Derzeit verwenden Agenturen Tags und Kategorien, die manuell festgelegt und aktualisiert werden. Viel Zeit wird daher mit dem Tagging und dem manuellen Hinzufügen von Daten verschwendet, was zu einer ineffizienten Nutzung der Humanressourcen führen kann.
Die Berechnung des tf-idf-Scores aller Wörter und die Verwendung der Wörter mit dem höchsten Score als Tags kann verwendet werden. Die Implementierung von NLP hilft bei der Entitätsextraktion des gesamten Inhalts und dem Abrufen wichtiger Wörter. Diese können als Tags für verwandte Inhalte verwendet werden.
Hier ist die vollständige POS-Tag-Liste:
| CC | koordinierende Konjunktion |
| CD | Kardinalzahl |
| DT | Bestimmer (Determinator) |
| EX | existentielles "es gibt" (wie: "es gibt" ... man kann es sich wie "es existiert" vorstellen) |
| FW | Fremdwort |
| IN | Präposition/subordinierende Konjunktion |
| JJ | Adjektiv 'groß' |
| JJR | Adjektiv, Komparativ 'größer' |
| JJS | Adjektiv, Superlativ 'am größten' |
| LS | Listenmarkierung 1) |
| MD | Modalverb könnte, wird |
| NN | Nomen, Singular 'Schreibtisch' |
| NNS | Nomen Plural 'Schreibtische' |
| NNP | Eigenname, Singular 'Harrison' |
| NNPS | Eigenname, Plural 'Amerikaner' |
| PDT | Prädeterminator 'alle Kinder' |
| POS | Possessivendung Elternteil |
| PRP | persönliches Pronomen Ich, er, sie |
| PRP$ | Possessivpronomen mein, sein, ihr |
| RB | Adverb sehr, still, |
| RBR | Adverb, Komparativ besser |
| RBS | Adverb, Superlativ am besten |
| RP | Partikel aufgeben |
| TO | zu gehen 'zu' dem Laden. |
| UH | Interjektion Ähhhh |
| VB | Verb, Grundform nehmen |
| VBD | Verb, Vergangenheitsform, nahm |
| VBG | Verb, Gerundium/Partizip Präsens nehmend |
| VBN | Verb, Partizip Perfekt genommen |
| VBP | Verb, Sing. Präsens, nicht-3d nehmen |
| VBZ | Verb, 3. Person Sing. Präsens nimmt |
| WDT | wh-Bestimmer welche |
| WP | wh-Pronomen wer, was |
| WP$ | Possessiv-wh-Pronomen wessen |
| WRB | wh-Adverb wo, wann |
Chunking: Auch Shallow Parsing genannt, mit Chunking kann man Wortarten und kürzere Phrasen (wie Nominalphrasen) identifizieren. Chunking-Gruppen implizieren hier, dass das Token in größere Tokens oder Einheiten zerlegt wird.
Um einen Chunk zu erstellen, müssen wir zuerst die Grammatik mit dem regulären Ausdruck und dem Tag-Muster (ein POS-Tag in spitzen Klammern) schreiben und dann einen Chunk-Parser erstellen.
Der Parser gibt ein nltk.tree-Objekt zurück, das mit dem NP (unser Chunk-Muster) gekennzeichnet ist, das wir durchlaufen müssen, um die Entität aus dem Baum zu extrahieren.
Der folgende Code-Stub extrahiert die Entität aus einem Satz:
>>> def extract_NN(sent):
grammar = r"""
NBAR:
# Nouns and Adjectives, terminated with Nouns
{<NN.*>*<NN.*>}
NP:
{<NBAR>}
# Above, connected with in/of/etc...
{<NBAR><IN><NBAR>}
"""
chunker = nltk.RegexpParser(grammar)
ne = set()
chunk = chunker.parse(nltk.pos_tag(nltk.word_tokenize(sent)))
for tree in chunk.subtrees(filter=lambda t: t.label() == 'NP'):
ne.add(' '.join([child[0] for child in tree.leaves()]))
return ne
>>> extract_NN(text)
{'health', 'Pythonic'}
Während Content-Tagging einer der oben genannten Anwendungsfälle ist, gibt es verwandte Probleme wie Kategorisierung, Zusammenfassung, SEO, die meist mit menschlicher Ineffizienz zusammenhängen, die mit der Implementierung überwunden werden kann.
Zusammenfassung: Wird für Teaser-Modi, Facebook-Posts oder -Beschreibungen, Twitter-Karten verwendet. Derzeit wird die Zusammenfassung entweder manuell geschrieben oder das System nimmt die Anfangsabsätze des Artikels auf, was ihn sehr anfällig für Ineffizienz macht. Mit dem Auto-Summarizer kann die Maschine die Zusammenfassung einfach analysieren und aus dem Text schreiben, wobei die Schlüsselwörter, Stimmungen und die Kernaussage des Inhalts berücksichtigt werden.
Es gibt verschiedene Algorithmen, um die Zusammenfassung für einen bestimmten Inhalt zu erstellen, die in abstraktive und extraktive Algorithmen unterteilt werden können. Mit der Gensim-Bibliothek von Python kann die Zusammenfassung abgerufen und an verschiedenen Stellen verwendet werden.
SEO: In ähnlicher Weise können NLP-Algorithmen und -Bibliotheken verwendet werden, um Meta-Beschreibungen, Abstraktionen, Schlüsselwörter und auch Microdata zu generieren, die verwendet werden können, um Inhalte mit schema.org-Spezifikationen abzubilden.
Sentimentanalyse: Untersuchung des Inhalts (Texte, Bilder und Videos) und Identifizierung der emotionalen Perspektive innerhalb des Inhalts. Das Programm kann die Haltung des Autors als positiv, negativ oder neutral identifizieren und klassifizieren. Dies ist hilfreich für Medienverlage, die die emotionale Perspektive der Website insgesamt ausgleichen müssen.
Wir können deutlich sehen, dass die extrahierten Entitäten `Health` und `Pythonic` sind, die als NN (Nomen) und NNP (Eigenname) gekennzeichnet wurden.
Hier ist die Zusammenfassung:
- Named Entity Recognition ist eine Form des Chunking.
- Das Nltk-Standard-pos_tag verwendet das PennTreebank-Tagset, um die Tokens zu taggen. Sehen Sie sich dies an, um die vollständige Bedeutung des POS-Tagsets zu erfahren. Sie können hier mehr erfahren: hier
- Hier habe ich das Beispiel des Regex-basierten Chunking gezeigt, aber nltk bietet mehr Chunker, der trainiert wird oder trainiert werden kann, um die Tokens zu chunkieren.
- Wir können auch den Typ der Entität mit NLTK finden, aber es ist nicht genau.
OpenSense Labs hat ein Modul 'Intelligente Content-Tools' entwickelt, um den Inhalt zu personalisieren und drei Kernfunktionen bereitzustellen:
- Auto-Tagging
- Zusammenfassung
- Doppelte Inhalte prüfen
Geeignete Lösungen für Ihre organisatorischen Zwecke können gefunden werden und wir freuen uns, Ihre Anforderungen unter [email protected] zu hören.
(Das Projekt unterliegt nicht der Sicherheitsrichtlinie, bitte verwenden Sie es auf eigenes Risiko.)
Kontaktieren Sie uns unter [email protected] für mehr!

Newsletter abonnieren
Open-Source-Technologie begeistert Sie? Bleiben Sie mit Projekten auf dem Laufenden, die einen Unterschied machen.