
How to Produce High-Performance Serverless Applications

Jayati
Articles
Published on 29 Jul, 2019
6 min read
When we moved from the monolithic structures to serverless, organizations took a giant leap of faith and a breath of relief. But technology enthusiasts didn’t. There were serverless challenges that needed to be addressed.
With the thought that there’s always room for more improvements, they further wanted to cater to complex services that required a premium level of serverless frameworks.
In this blog, let’s take a step further in the serverless world and go beyond the basics. Here, we will be discussing the best practices that can maximize the utility of serverless application for your organization.

Beyond Serverless
The existing serverless platforms as we know them are simple applications that eliminated the need of monolithic infrastructures and lead to better development and deployment of projects. This cloud computing paradigm isolated the functions into containers that did not interact with each other. However, the established serverless practices that took shape stemmed few drawbacks in the process.
First, the cold start of the functions increased the latency rate of the serverless and inversely, the cost of the functions increased if the containers were kept ‘warm’ in order to reduce the startup latency for processing.
Further, the observations showcased that the non-existent communication between containers and functions didn’t go well with developers who weren’t used to it.
These practices propelled for an intervention that would upgrade the services, optimize the serverless frameworks and prove to be efficient than before.
Best Practices and Bursting Myths
Serverless experts go by these practices as the best of practices that can fetch high-performance application for your system. Regardless to mention, they can vary according to the nature and dynamics of your organization.
#1 Managing Code
Documentation of the changes that you conspire for your configurations is a task. Often the changes made by the developers aren’t documented or aren’t easy to comprehend in an intended manner at a later stage. All these confusions can be put to rest if you create YAML that defines your stack in a file which you can use to track changes whenever required.
#2 Logging is not Observability
Serverless brought in scaling as a major feature and scaling added slowness to complex structures that became prone to bugs.
As we know, logging and metrics of the system give an edge over the statistics and you can catch minutest of details and activities taking place in your Lambda. However, this power of logging and visibility didn’t come with observability, which is analyzing the system from outside and taking a panoramic view of the internal functions. Surely the tools equipped the application with best of metrics, but wholesome observability seemed to be missing.
Therefore, tools like Honeycomb and Espagon came up with measures that can aid you with facilitating observability and can give a better overview of your serverless operations.
Against the myth that serverless requires you to rewrite your code, the best practice is considered not to rewrite them.
#3 Use of Libraries
Along with the latency issues, the size of the zip file that contains the code is also a culprit that can reduce the functioning of your serverless. Using a lot of libraries for unnecessary tasks that can be created adds weight to the process and thus slows down the serverless application. Also, not all libraries can be trusted with the code and dependencies.
It is advised for the best of utilization that minimum libraries should be invested in and developers should build it on their own.
#4 Requesting What You Need
With its primary function to look for information, Lambda gets to work as soon as its triggered. The query goes around seeking relevant information for the requested content.
Nothing major can be done in this respect except making the parent request log out from the search.
#5 Rewriting the Code
Against the myth that serverless requires you to rewrite your code, the best practice is considered not to rewrite them. If your code is in JavaScript, it belongs to the highest order of languages already.
Your code in JavaScript is interpreted in the most performative manner and there are alternative ways to improve the performance of the code.
Therefore, do not attempt to rewrite the code for your application and try other measures to improve the performance.
#6 Single function
In order to scale your application in the best way possible, it is better not to use single function proxy. Since we have already established that serverless works best with services, the functionality of the application needs to be isolated. Surely the complexity of the management soars up but the DevOps with serverless was always a part of the plan.
#7 New Codes lead to More Testing
Tweaks and alterations have always seemed to be a part of the coding process. When the Lambda got complicated, developers started making changes in the configurations to put things at ease for the deployment. However, this made the code more complicated and slow as each change triggered a new trail of codes to be saved, deployed, and refreshed. Later, the waiting period for the fresh codes to show the changes also made it difficult to keep patience in check.
#8 Services over Connection
Serverless works with services. Connections like RDBMS doesn’t work for serverless applications. The agility and rapid responses of the services are most suitable for the FaaS than the connections that bottleneck the functions. Connections here become needless also from the point of cold starts that lead to latency issues.
Therefore, it is best not to use connections unless you absolutely have to.
#9 Data flow is Important
A data layer is a significant part of the serverless. Since the functions are always running, the data in the system flows too. Therefore, you should treat the data like it is in motion and not as something that can become stagnant or rigid. It is best to avoid querying of data in a data lake that hampers the scaling too.
Use Case
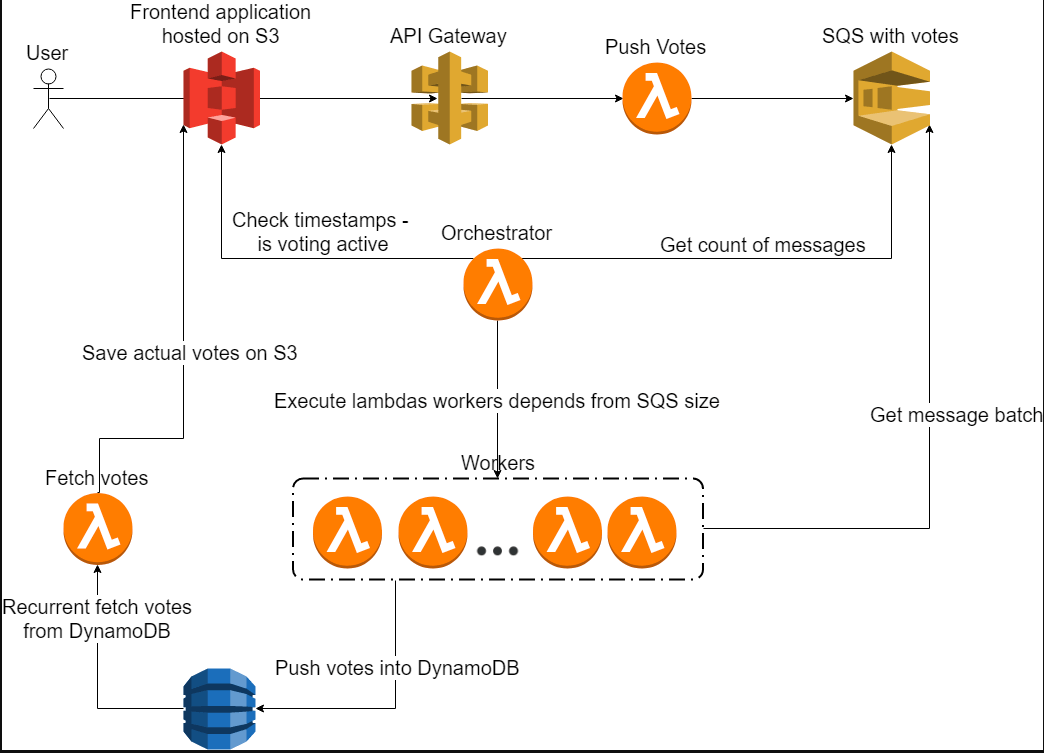
In order to obtain a high-performance system, a Serverless approach was adopted and build it with native AWS component by a developer.
For the frontend, the S3 scaled seamlessly even on a heavy load. Its features ask you to pay only for real traffic, thus the development process becomes very cheap.
They further built a simple single page application in Vue.js for the form.
Similarly, for the backend, an API Gateway service serves as a proxy for one of the lambda functions used.
In a few more series of steps (diagram below), the AWS platform provided a vast amount of services ready to integrate easily with various solutions.
Conclusion
Though these practices come in handy for sure, they are not the ‘’only practices’’. There’s always more scope to experiment, improve and learn.
Do you know any other serverless practices that can be of help to the community? Comment below or share them on our social networks: Facebook, Twitter, and LinkedIn.
Subscribe
Related Blogs
Workforce Management Tool: Features, Benefits & Complete Guide

“Simply Manage is a workforce management tool designed to streamline workflows across teams, making time tracking, resource…
Trek n Tech Annual Retreat 2025: A 7-Day Workcation of OSL

OSL family came together for the Trek n Tech Annual Retreat 2025, a 7-day workcation set amidst the serene beauty of…
Exploring Drupal's Single Directory Components: A Game-Changer for Developers

Web development thrives on efficiency and organisation, and Drupal, our favourite CMS, is here to amp that up with its…