
Performing Federated Search with Drupal and Apache Solr

Jayati
Drupal
Published on 13 Mar, 2019
5 min read
The Internet is an infinity pool of content and your organization wants to draw only the most useful and relevant information.
With Artificial Intelligence (AI), users expect to gain access to a one-stop library where search functionality is one of the most important implementations on the website. Yet often we fail to obtain the needed information on many engines including the best of search appliances. These failures can include - technical, cultural and maybe personal reasons too. A standard content search often takes too long if there are no optimization practices applied which in turn makes the visitors irritated due to the waiting time. The futility of time in this process is the biggest failure leading to staggering costs at the enterprise’s end. What we need is a tool that lets us search for multiple searchable resources.
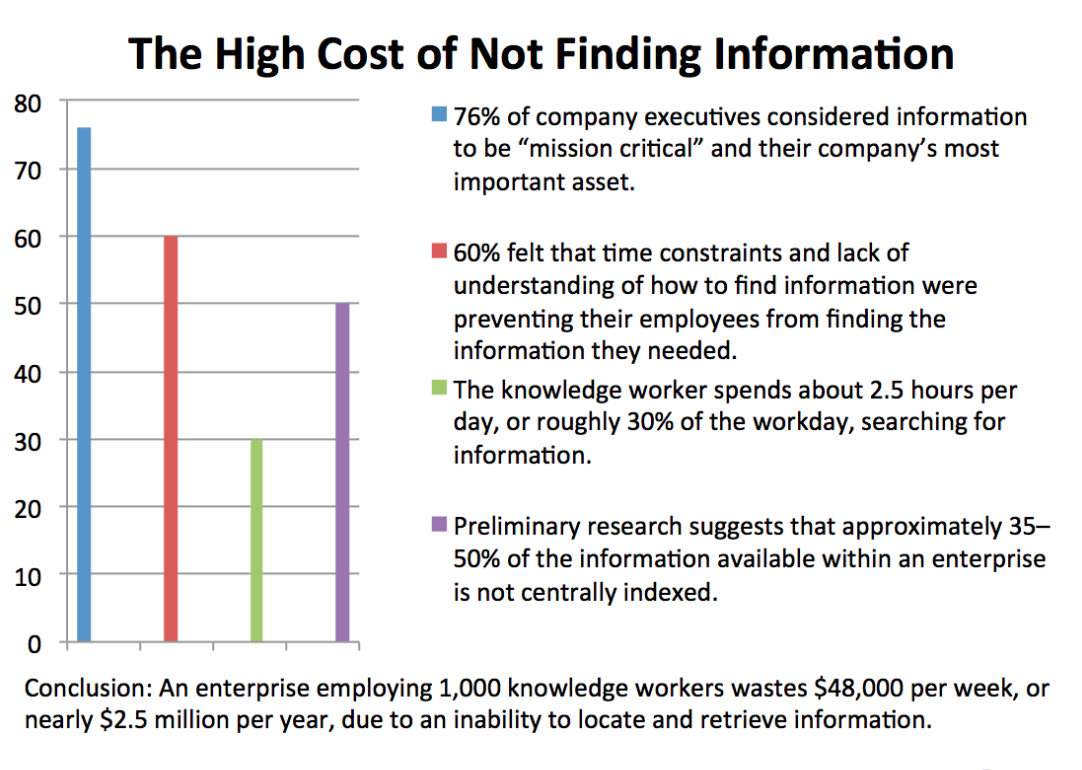
Among dozens of suitable tools in the market, only a few of them can deliver the quality that can reduce the above statistics, which states that an enterprise wastes $48,000 per week due to inability to locate and retrieve information when 35-50% of the information available within an enterprise is not centrally indexed. Let’s explore the options
Demystifying Federated Search
In the dire need of a highly available and scalable search service, we introduce Federated search. An application that allows you to index multiple sites (including Drupal) to a single search application and gives consistent results. It has three main parts:
- Content indexing via Drupal integration (provided)
- Result serving via React application (provided)
- Data storage in a Solr backend (required)
When Drupal, Solr, and React come together, they enable indexing of data from arbitrary sources, standardize it, and present it in an easily consumable way. This leads to flexibility for site administrators and a better experience for users too. Here’s an example:
Within a traditional search system(Fig 1; Diagram below), when the user makes a single query request, it shows limited information from a single site only. However, with a federated search (Fig 2), the scalability increases by leveraging an existing index. All queries are submitted to a subset of collections so that each remote application can undertake the query against its own document repository. The final output, as a result, is returned in a collection and merged into a single integrated list.
Why Federated Search?
Search is a business-critical feature used for navigating an organization’s platform of sites and Federated search technology provides the interface for diverse information resources that yields manifold benefits including:
Efficiency
Time is of importance and a federated search engine lets users save a huge chunk of it by performing multiple searches on the user’s behalf. It specialises in finding the content from different sources and bringing it on one single result page.
Quality of Results
The quality of the result is a huge factor for the success of the federated search. The algorithm of the engines works in a manner to enhance the quality of the output while covering numerous sources in the process.
Current Content
The federated search engines show content in real-time. The frequently changing data is updated in the federated search as the researchers for whom the up-to-the-minute content is crucial, it becomes easier to find real-time data. Also, if the content owners update their source, the same is reflected to the researcher on the very next query.
Dynamic, Diverse and Engaging Information
The content from diverse sources like catalogs, websites and libraries are accumulated at a single and integrated page by the federated search engine which gives complete information about the query generated by the researcher.
Retain Customers
By enabling to deliver search results from multiple searchable content providers, simultaneously, via one search query, federated search retains customers who regularly need to save on time and gain real-time and high-quality results.

Enterprise Search vs Federated Search
The two terms, Enterprise Search and Federated Search, are used interchangeably by some vendors and one is ought to get confused in the process. However, they both are quite different in an environment where organizations perform multiple search products or integrate various information management systems that can embed their own search facilities.
|
|
Enterprise Search |
Federated Search |
|
Content Source |
Content is indexed locally and stored in a database. |
Utilizes the search results provided by an external system |
|
Indexing |
Documents are available by the indexer |
Relies on external system’s indexing capabilities |
|
Access |
To access and index documents locally, it requires loading the document to a locally accessible location |
The indexing process is handled by the remote system. And this includes the regular indexing to keep the index up-to-date |
Performing Federated Search
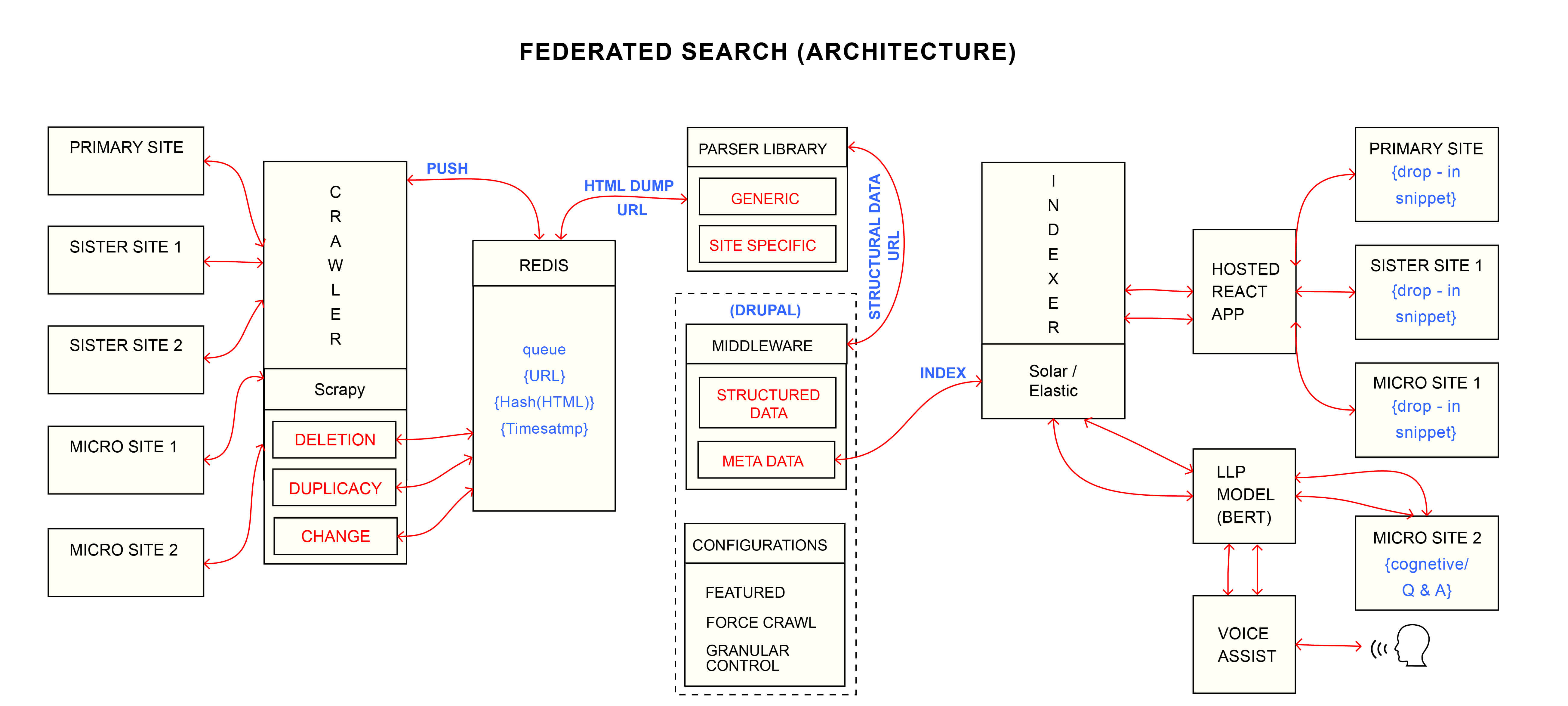
OpenSense Labs initiated a federated search via Apache Solr and Drupal for three different sites. Here’s a step by step explanation of how the search can be performed:
The crawler captures data from Site 1, Site 2 and Site 3.
The selected data is put through the middle-ware (a PHP framework) where it is identified, filtered and categorized.
Next, the open source platform (you can choose either Apache Solr or ElasticSearch) acts as a look-up service provider to index the data in a single page result for the user on the CMS.
The Js script is applied to the server for converting data of different languages(python, PHP or other) and presenting it in a uniform manner.
Apache Solr
‘Apache Solr is an enterprise-ready, fast and highly scalable tool that can create sophisticated application to deliver high performance.’
Enterprise-ready, fast and highly scalable, Apache Solr is an open source search platform that creates a sophisticated application to deliver high performance to provide distributed indexing, replication, and load-balanced querying with a centralized configuration. By using the Solr configuration supplied with the Search API, Solr allows greater understanding of Drupal, it’s field types and the data they contain.
ElasticSearch

‘Elasticsearch is incredibly fast and can facilitate with added advantages when integrated with Drupal.’
Including a simple RESTful API, Elasticsearch is an equal alternative to Apache Solr. It is incredibly fast and can facilitate added advantages when integrated with Drupal.
The transmitting of data from Drupal to Elasticsearch enables search API to have full control over the index via the backend interface. Thus, the first step is to decide on the Search API module.
Conclusion
With the plethora of data being added on the web everyday, it’s only going to ascend from here on. What researchers need now more than ever is a tool for searching and analysing data in real-time, like Apache Solr or Elasticsearch as both support scalable and high availability architectures on Cloud hosting infrastructure.
We at OpenSense Labs understand your enterprise’s needs and cater to various services for our clients. Get in touch at [email protected].
Subscribe
Related Blogs
What is HTMX & How it Works for Server-Driven Web Interfaces?

“HTML was designed to explain user interactions. HTMX pushes that behavior back where it started, the markup itself." This…
DrupalCon Chicago: Key Product & AI Updates

“The DrupalCon Chicago keynote looks back at Drupal’s 25-year journey while outlining how the platform is evolving. It…
DrupalCamp Delhi Returns After 6 Years: Here’s What to Expect

“After the COVID period, this marks the first time the camp is returning to Delhi. Over the years, the camp and the local…