Underlying Principles Of Observability

Laila Mahran
Generic
Published on 24 Jul, 2020
5 min read
At its core, observability is a term used to describe the process of measuring what is going on within the internal state of a piece of software or another IT-based system by taking a closer look at everything happening outside of it. In other words, it's a form of control theory that dictates that you'll be able to answer any question about what is happening inside of a web application by observing what is going on with the outside - all without having to ship even a single line of new code.

The Objectives of Observability
If you had to sum up the major objectives of observability in just a single word, that word would undoubtedly be "understanding."
By making systems fully observable during the development process, literally anyone on a team can easily navigate from "effect" to "cause" in a production system at any time. This means that you don't just get a better understanding of what is happening in a literal sense. You also have access to information about why certain things are occurring, thus allowing developers to better understand multi-layer architectures within the context of what is slow, what is broken, and what steps need to be taken in order to maximize and improve performance across the board.
The Core Components of Observability
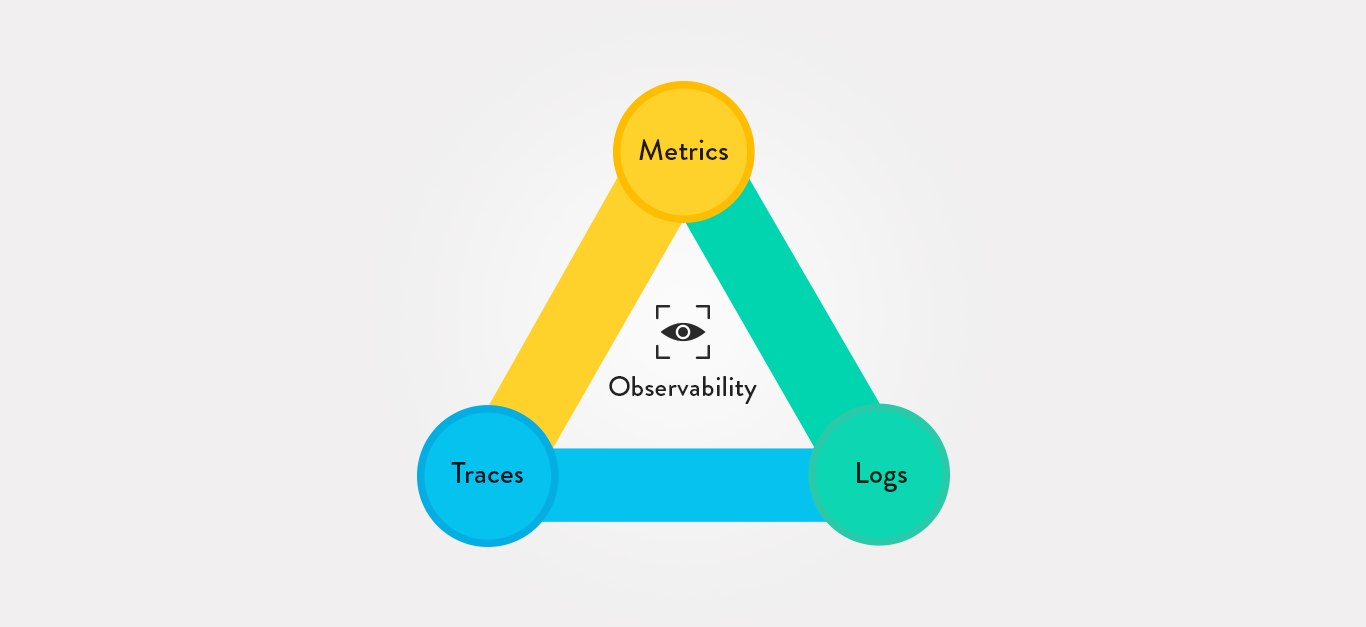
One of the core components of this concept ultimately comes down to the telemetry data through which these concepts are made observable in the first place. Remember that you're talking about a scenario where you can better understand how something works internally by taking a closer look at external factors and behaviors. More often than not, the telemetry data derived from those external factors takes the form of things like:
- Logs. These are lines of text that can be both structured or unstructured depending on the circumstances, all of which are created by a web application in response to some type of event taking place within the code itself. In general, a log is a distinct record of an event that happened - usually with other specific attributes like time information.
- Metrics. These are usually calculated or aggregated over a period of time specified by developers and provide deeper insight and meaning behind events that are occurring. Metrics can tell you everything from how much memory is being used by a particular process to how many requests per second are being handled - all in a way that provides the context necessary to manage tasks like troubleshooting, among others.
- Traces. These are an essential part of the observability concept, as they again provide context for other telemetry data that you may be working with. Traces - which show the activity for individual requests or actions as they flow through an app - can help identify which particular logs are relevant to the specific issue you're trying to troubleshoot, or which metrics are most valuable given what you're trying to accomplish at the moment.
When you combine the data derived from sources like these, you suddenly have a much more vivid (and proactive) picture of what is actually going on with a web application - certainly beyond what a technique like traditional monitoring can provide.
The problem with monitoring is that it is passive by its very nature. You wait for something to break, then fix it. But more than that, monitoring tools are built to maintain static environments with very little variation - meaning the systems themselves experience little change over time. More often than not, this simply isn't the way modern development environments work any longer.
The core pillars of observability, on the other hand, give you understanding actively and allow you to ask questions based on a particular hypothesis you may have. But most importantly, they're built with dynamic environments with changing complexity in mind - something that is far better suited for modern development best practices, particularly in terms of web apps built on microservices.
Implementing Observability
The key process of implementing observability across your development environment ultimately comes down to embracing tools that allow you to support and derive insight from those core pillars outlined above.
First, you need to choose the type of observability platform that fits your specific needs - one that condenses all of the telemetry data from metrics, logs, and traces into easy-to-understand and visual dashboards. Then, you need to monitor the metrics that really matter - meaning ones that not only relate to issues you've already experienced but also those that you could experience in the future.
After embedding observability into the very DNA of your incident management process, you can then move onto the most important implementation step of all: establishing a culture of observability across your business.
In no uncertain terms: these observability tools may be powerful, but without the processes in norms in place to make sure that people actually use them, you won't be able to uncover a fraction of the insight you were expecting. But by following these four core implementation steps, you'll not only be headed in the right direction regarding implementing observability throughout your business.
You'll finally have the confidence you need to create better, more customer-focused products at greater speeds than ever before, ultimately allowing you to keep your customers happy with less downtime, incredible new features, and the faster systems they've come to expect from you.
In the end
What is observability? It’s important to think about observability less as an overall technique and more in terms of what it helps you unlock. More than anything, observability is about generating an almost unprecedented level of visibility into a system, allowing anyone on a development team to know more than just the fact that a problem is happening. They also know why that issue is occurring, which means that they also know the most important piece of information of all: what they need to do to go in and fix it.
Subscribe
Related Blogs
Why should you prioritize lean digital in your company?

We are living in an era where the change and innovation rate is just so high. If you want your organization to reach new…
How to measure your open source program’s success?

Along with active participation, it is very important to look after the ROI of open-source projects, programs, and…
Understanding the significance of participating in open-source communities

Do you think contributing to the open source community can be difficult? I don’t think so. Do you have to be employed by a…