
Grundprinzipien der Observability
Im Kern beschreibt der Begriff Observability (Beobachtbarkeit) den Prozess, bei dem der interne Zustand einer Software oder eines anderen IT-basierten Systems gemessen wird, indem alles, was außerhalb des Systems geschieht, genauer betrachtet wird. Mit anderen Worten, es handelt sich um eine Form der Kontrolltheorie, die besagt, dass Sie jede Frage darüber beantworten können, was im Inneren einer Webanwendung vor sich geht, indem Sie beobachten, was außerhalb der Anwendung geschieht – und das, ohne auch nur eine einzige Zeile neuen Code ausliefern zu müssen.

Die Ziele der Observability
Wenn man die Hauptziele der Observability mit nur einem Wort zusammenfassen müsste, wäre dieses Wort zweifellos "Verständnis".
Indem Systeme während des Entwicklungsprozesses vollständig beobachtbar gemacht werden, kann buchstäblich jeder in einem Team jederzeit problemlos von "Wirkung" zu "Ursache" in einem Produktionssystem navigieren. Das bedeutet, dass Sie nicht nur ein besseres Verständnis dafür bekommen, was im wahrsten Sinne des Wortes geschieht. Sie haben auch Zugriff auf Informationen darüber, warum bestimmte Dinge geschehen, wodurch Entwickler mehrschichtige Architekturen besser im Kontext dessen verstehen können, was langsam ist, was defekt ist und welche Schritte unternommen werden müssen, um die Leistung auf breiter Front zu maximieren und zu verbessern.
Die Kernkomponenten der Observability
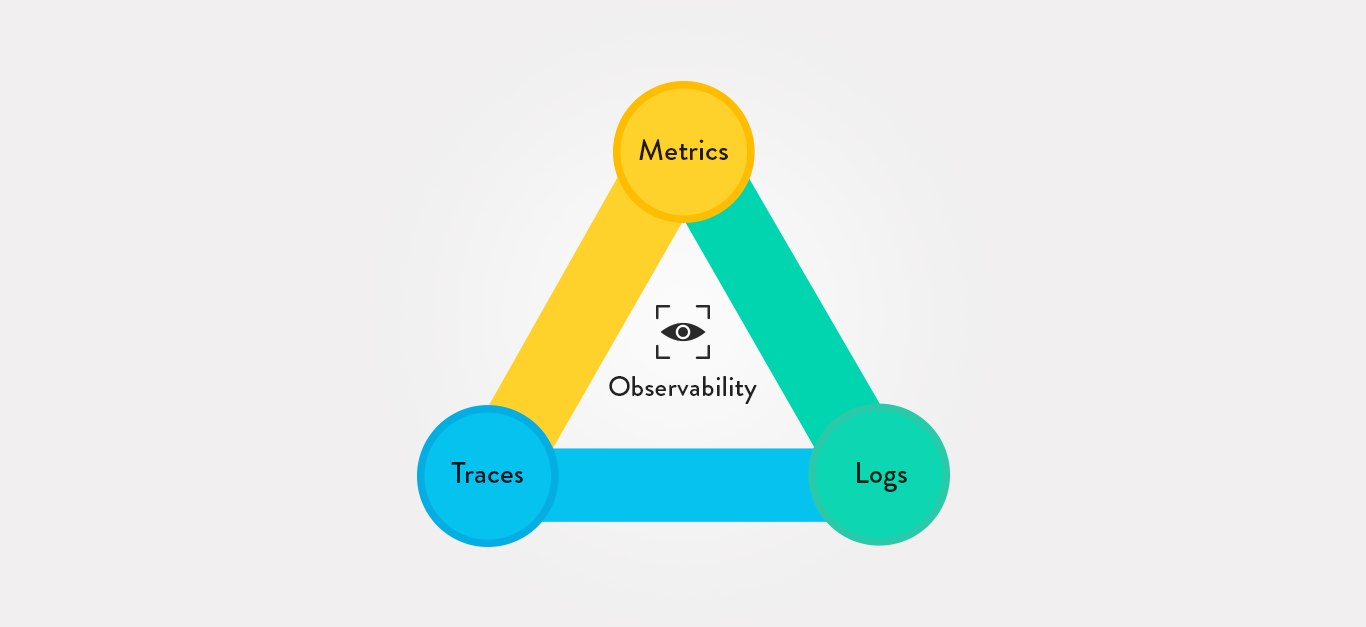
Eine der Kernkomponenten dieses Konzepts ist letztlich die Telemetrie, durch die diese Konzepte überhaupt erst beobachtbar gemacht werden. Denken Sie daran, dass es sich um ein Szenario handelt, in dem Sie besser verstehen können, wie etwas intern funktioniert, indem Sie externe Faktoren und Verhaltensweisen genauer betrachten. In den meisten Fällen nehmen die aus diesen externen Faktoren abgeleiteten Telemetriedaten die Form von Dingen wie den folgenden an:
- Logs (Protokolle). Dies sind Textzeilen, die je nach den Umständen sowohl strukturiert als auch unstrukturiert sein können und die alle von einer Webanwendung als Reaktion auf ein Ereignis erstellt werden, das innerhalb des Codes selbst stattfindet. Im Allgemeinen ist ein Log ein eindeutiger Datensatz eines Ereignisses, das stattgefunden hat - in der Regel mit anderen spezifischen Attributen wie Zeitinformationen.
- Metriken. Diese werden in der Regel über einen von Entwicklern festgelegten Zeitraum berechnet oder aggregiert und liefern tiefere Einblicke und Bedeutungen hinter den Ereignissen, die stattfinden. Metriken können Ihnen alles darüber sagen, wie viel Speicher von einem bestimmten Prozess verwendet wird oder wie viele Anfragen pro Sekunde bearbeitet werden - und das alles auf eine Weise, die den Kontext liefert, der für die Verwaltung von Aufgaben wie der Fehlerbehebung erforderlich ist.
- Traces (Ablaufverfolgungen). Diese sind ein wesentlicher Bestandteil des Observability-Konzepts, da sie wiederum Kontext für andere Telemetriedaten liefern, mit denen Sie möglicherweise arbeiten. Traces - die die Aktivität für einzelne Anfragen oder Aktionen zeigen, während sie durch eine App fließen - können helfen, die spezifischen Logs zu identifizieren, die für das spezifische Problem relevant sind, das Sie zu beheben versuchen, oder welche Metriken am wertvollsten sind, je nachdem, was Sie im Moment erreichen wollen.
Wenn Sie die Daten aus solchen Quellen kombinieren, erhalten Sie plötzlich ein viel lebendigeres (und proaktiveres) Bild davon, was tatsächlich mit einer Webanwendung vor sich geht - sicherlich über das hinaus, was eine Technik wie das traditionelle Monitoring leisten kann.
Das Problem beim Monitoring ist, dass es von Natur aus passiv ist. Man wartet darauf, dass etwas kaputt geht, und repariert es dann. Aber darüber hinaus sind Monitoring-Tools darauf ausgelegt, statische Umgebungen mit sehr geringen Schwankungen aufrechtzuerhalten - was bedeutet, dass sich die Systeme selbst im Laufe der Zeit kaum verändern. In den meisten Fällen ist dies einfach nicht mehr die Art und Weise, wie moderne Entwicklungsumgebungen funktionieren.
Die Kernsäulen der Observability hingegen vermitteln Ihnen aktiv ein Verständnis und ermöglichen es Ihnen, Fragen auf der Grundlage einer bestimmten Hypothese zu stellen, die Sie möglicherweise haben. Aber vor allem sind sie für dynamische Umgebungen mit wechselnder Komplexität konzipiert - etwas, das viel besser für moderne Best Practices in der Entwicklung geeignet ist, insbesondere im Hinblick auf Webanwendungen, die auf Microservices basieren.
Implementierung von Observability
Der wichtigste Prozess bei der Implementierung von Observability in Ihrer Entwicklungsumgebung besteht letztlich darin, Tools einzusetzen, die es Ihnen ermöglichen, die oben genannten Kernsäulen zu unterstützen und Erkenntnisse daraus zu gewinnen.
Zunächst müssen Sie die Art von Observability-Plattform auswählen, die Ihren spezifischen Bedürfnissen entspricht - eine, die alle Telemetriedaten aus Metriken, Logs und Traces in leicht verständliche und visuelle Dashboards zusammenfasst. Dann müssen Sie die Metriken überwachen, die wirklich wichtig sind - d. h. solche, die sich nicht nur auf Probleme beziehen, die Sie bereits erlebt haben, sondern auch auf solche, die Sie in Zukunft erleben könnten.
Nachdem Sie die Observability in die DNA Ihres Incident-Management-Prozesses eingebettet haben, können Sie zum wichtigsten Implementierungsschritt von allen übergehen: der Etablierung einer Kultur der Observability in Ihrem Unternehmen.
Um es ganz klar zu sagen: Diese Observability-Tools mögen zwar leistungsstark sein, aber ohne die Prozesse und Normen, die sicherstellen, dass die Leute sie tatsächlich nutzen, werden Sie nicht einen Bruchteil der Erkenntnisse gewinnen, die Sie erwartet haben. Aber wenn Sie diese vier Kernschritte der Implementierung befolgen, sind Sie nicht nur auf dem richtigen Weg, die Observability in Ihrem gesamten Unternehmen zu implementieren.
Sie werden endlich das nötige Vertrauen haben, um bessere, kundenorientiertere Produkte schneller als je zuvor zu entwickeln, so dass Sie Ihre Kunden mit weniger Ausfallzeiten, unglaublichen neuen Funktionen und den schnelleren Systemen, die sie von Ihnen erwarten, zufriedenstellen können.
Fazit
Was ist Observability? Es ist wichtig, Observability weniger als eine allgemeine Technik zu betrachten, sondern mehr im Hinblick darauf, was sie Ihnen ermöglicht. Mehr als alles andere geht es bei Observability darum, ein fast beispielloses Maß an Transparenz in ein System zu bringen, so dass jeder in einem Entwicklungsteam mehr weiß als nur die Tatsache, dass ein Problem auftritt. Sie wissen auch, warum dieses Problem auftritt, was bedeutet, dass sie auch die wichtigste Information von allen kennen: was sie tun müssen, um es zu beheben.

Newsletter abonnieren
Open-Source-Technologie begeistert Sie? Bleiben Sie mit Projekten auf dem Laufenden, die einen Unterschied machen.



