
Erklärbare KI-Tools: SHAPs Stärke in Der KI
Wissen Sie, was erklärbare KI-Tools sind?
Erklärbare KI-Tools sind Programme, die zeigen, wie eine KI ihre Entscheidungen trifft. Sie helfen Menschen, den Entscheidungsprozess von KI zu verstehen, was Vertrauen schafft und eine bessere Verwaltung und Anpassung von KI-Systemen ermöglicht.
In diesem Blog sprechen wir über erklärbare KI-Tools wie SHAP und dessen Methodik, die einen robusten Rahmen bietet, um zu verstehen, wie jedes Merkmal die Vorhersagen eines Modells beeinflusst.
Bevor wir fortfahren, hier das größere Bild: Erklärbarkeit ist eine der eigentlichen Säulen von AI Governance. Ein Modell, das man nicht erklären kann, kann man auch nicht kontrollieren oder für die Compliance freigeben. Wenn Sie sehen möchten, wie wir Unternehmen dabei helfen, diese Art von Verantwortlichkeit in ihre KI-Systeme einzubauen...
Schauen wir uns an, wie erklärbare KI-Tools wie SHAP funktionieren!
Erklärbare KI-Tools: Was ist SHAP?
SHAP (SHapley Additive exPlanation) ist eine leistungsstarke und weit verbreitete Methode zur Erklärung von Machine-Learning-Modellen. Es hilft, die Ausgabe von Machine-Learning-Modellen, insbesondere komplexen ML-Modellen (wie Deep Learning oder Ensemble-Modellen), zu interpretieren, indem es eine Möglichkeit bietet, den Beitrag jedes Merkmals zur Vorhersage eines Modells zu verstehen.
Durch die Nutzung von Shapley-Werten weist SHAP jedem Merkmal einen fairen Beitrags-Score zu und gewährleistet so Transparenz bei der Modellentscheidung. Es verwendet Shapley-Werte, ein Konzept aus der kooperativen Spieltheorie, das eine faire Methode zur Verteilung der Last – in unserem Fall der Vorhersage des ML-Modells – auf die beitragenden Merkmale bietet.
Die Integration von SHAP in unseren Workflow verbessert die Interpretierbarkeit des Modells und erhöht so das Vertrauen. Da ML-Modelle immer komplexer werden, ist ein klares Verständnis, wie Merkmale zu Vorhersagen beitragen, unerlässlich, um die Modellleistung zu verbessern und Rechenschaftspflicht zu gewährleisten.
Insgesamt sind erklärbare KI-Tools wie SHAP unverzichtbare Hilfsmittel, um die Lücke zwischen komplexen ML-Modellen und dem menschlichen Verständnis zu schließen. Durch den Einsatz erklärbarer KI-Tools wie SHAP können KI-/ML-Ingenieure und Datenwissenschaftler fundiertere Entscheidungen treffen, ihre Modelle verfeinern und letztendlich transparentere und zuverlässigere KI entwickeln.
Die Transparenz, die SHAP bietet, ist von großem Nutzen, um komplexe ML-Modellvorhersagen und den Einfluss der Merkmale auf die Modellausgabe verständlich zu machen.
Erklärbare KI-Tools wie SHAP sind beeindruckend, da sie Menschen dabei helfen, zu verstehen, wie KI ihre Entscheidungen trifft.
Erklärbare KI-Tools: Warum SHAP verwenden?
Da die Technologie immer komplexer wird und mit der Einführung von LLMs in der KI die Interpretierbarkeit der Modellergebnisse zunehmend schwieriger wird.
Ein Modell kann durch seine zugrunde liegende Mathematik und die gegebene Architektur verstanden werden, aber seine Entscheidungsfindung verständlich zu machen, wird schwierig.
Hier kommt ein leistungsstarkes Python-Modul namens SHAP ins Spiel, das nicht nur eine interpretierbare Möglichkeit bietet, das Modell zu verstehen, sondern auch die Bedeutung eines Merkmals in Black-Box-Modellen wie ML-Modellen aufzeigt. Es hilft, den Prozess der Feinabstimmung des Modells zu optimieren.
Lesen Sie auch:
1. KI-Chatbot: Präzision und Persönlichkeit gestalten
2. KI-Fairness: Ein tiefer Einblick in Microsofts Fairlearn Toolkit
3. AIOps: Künstliche Intelligenz in DevOps nutzen
4. Unternehmen verändern mit Künstlicher Intelligenz und Drupal
Wie interpretiert man SHAP-Werte?
Bevor wir zur praktischen Anwendung übergehen, wollen wir verstehen, wie Shapley-Werte berechnet werden. Wir haben ein Transformer-Modell verwendet, um den Wert (Sentiment) basierend auf Merkmalen vorherzusagen. In unserem Fall sind die Merkmale einzelne Wörter in einem Satz. Der Shapley-Wert für ein Merkmal (Wort) ist der Durchschnitt seiner marginalen Beiträge über alle Teilmengen von Merkmalen (Wörtern).
Der Shapley-Wert für Merkmal i (oder Wort i) im Modell kann ausgedrückt werden als:

- Φi→ Shapley-Wert
- N → Menge der Merkmale
- S → Eine Teilmenge von Merkmalen, die i ausschließt
- |N|, |S| → Anzahl der Elemente in N und S
- f(S) → Modellvorhersage für S Merkmale
- f(S ⋃ {i})→ Modellvorhersage, wenn {i} zu S Merkmalen hinzugefügt wird
Nehmen wir ein Beispiel: „OSL ist ein dynamisches Team“, was Textkommentaren im Datensatz entspricht.
Wörter im Satz:
w1 = „OSL“
w2 = „ist“
w3 = „ein“
w4 = „dynamisches“
w5 = „Team“
Nach der Tokenisierung durch unser geladenes Modell wird jedem Wort im Satz ein Score zugewiesen. Diese Scores sind nichts anderes als f(x).
Sehen wir uns nun an, wie wir den Shapley-Wert für das Wort „dynamisches“ im obigen Satz berechnen.
Teilmengen ohne „dynamisches“: Betrachten Sie Teilmengen wie {w1, w2}, {w1, w3} usw.
Marginaler Beitrag für jeden Beitrag:
Für Teilmenge S = {w1, w2},
berechnen Sie:
f(S) = Vorhersage mit „OSL ist“
f(S ∪ {w4}) = Vorhersage mit „OSL ist dynamisches“
Der marginale Beitrag für das Wort „dynamisches“ ist die Differenz: f(S {w4}) - f(S)
Für alle Teilmengen wiederholen: Berechnen Sie für jede Wortkoalition, die „dynamisches“ ausschließt, den marginalen Beitrag.
Marginalen Beitrag mitteln: Sobald Sie die marginalen Beiträge für alle möglichen Teilmengen haben, mitteln Sie diese, um den Shapley-Wert für das Wort „dynamisches“ zu erhalten:
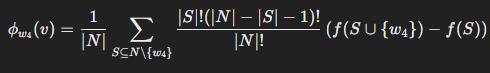
Wiederholen Sie die Schritte für alle verbleibenden Wörter, um jeweils deren Shapley-Wert zu erhalten.
CODE:

Begriffe in der SHAP-Interpretation verstehen
Basiswert: Repräsentiert die durchschnittliche Vorhersage des Modells auf dem Datensatz
Ausgabewert: Repräsentiert die endgültige Vorhersage des Modells für den spezifischen visualisierten Text.
Farbige Hervorhebungen: Wörter innerhalb des Textes werden mit verschiedenen Rottönen hervorgehoben.
1. Rot: Zeigt die Vorhersage des Modells in Richtung eines positiven Sentiments an. Die Intensität der roten Farbe entspricht dem Ausmaß des positiven Beitrags – ein dunkleres Rot bedeutet einen stärkeren positiven Einfluss.
2. Blau: Zeigt die Vorhersage des Modells in Richtung eines negativen Sentiments an. Die Intensität der blauen Farbe entspricht dem Ausmaß des negativen Beitrags – ein dunkleres Blau bedeutet einen stärkeren negativen Einfluss.
Nicht hervorgehobene Wörter hatten wenig bis keinen Einfluss auf die Vorhersage des positiven Sentiments.
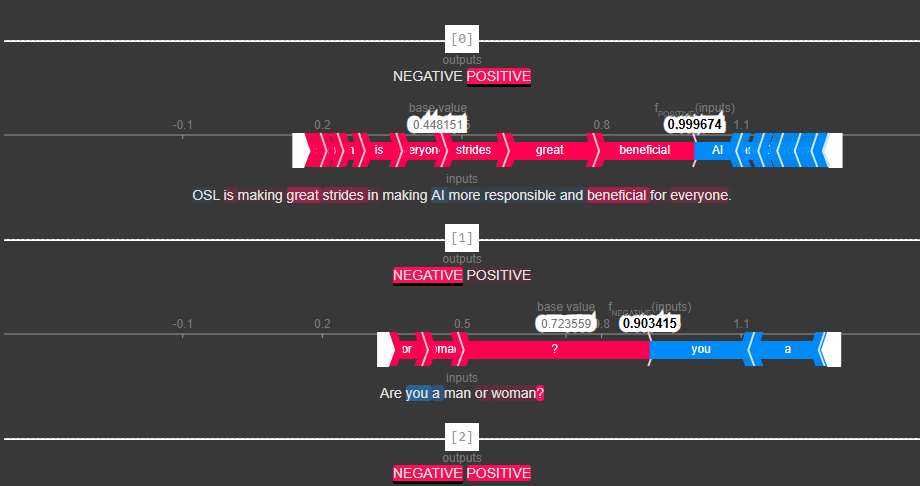
![]()




Im obigen Textplot (ein interaktiver Plot, bei dem der Beitrag jedes Merkmals zur Modellvorhersage sichtbar ist) wurde der Cursor auf 4 Wörter gesetzt:
Die ersten beiden Bilder zeigen einen Cursor, der auf „great (0.194)“ und „beneficial (0.215)“ platziert ist, welche zur positiven Natur des Sentiments beitragen.
Das dritte Bild zeigt einen Cursor, der auf „AI (-0.098)“ platziert ist und zeigt, wie negativ das Wort „AI“ die positive Natur des Sentiments beeinflusst.
Das letzte Bild zeigt den Cursor, der auf „making (0.007)“ platziert ist und einen vernachlässigbaren Einfluss auf die positive Natur des Sentiments hat.
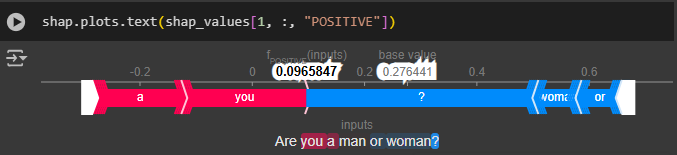
Es zeigt einen Force Plot, der speziell auf Textdaten zugeschnitten ist und den Beitrag zum positiven Sentiment hervorhebt. Die rot hervorgehobenen Wörter zeigen die Wörter, die zum positiven Einfluss des Sentiments beitragen, während die blauen den negativen Einfluss zeigen. Die graue Linie oder der Basiswert zeigt die durchschnittliche Vorhersage des Modells, die 0,448 beträgt. fPOSITIVE(inputs) liefert den positiven Score, den das Modell für den jeweiligen Text vorhergesagt hat, nämlich 0,99. Das Sentiment ist positiv, da fPOSITIVE(inputs) größer ist als der Basiswert. Ähnlich können wir für alle anderen Instanzen überprüfen, wie alle Merkmale, die zum Sentiment beitragen, vom Modell berechnet werden.
![]()
Ähnlich sind für „NEGATIV“, d.h. wie negativ ein Satz ist, die Werte dieselben, aber nur entgegengesetzt in Farbe und Vorzeichen für dieselben Wörter wie bei „POSITIV“. Es ist auch offensichtlich, da der Basiswert (0,55) größer ist als fNEGATIVE (inputs) (0,00032), was deutlich macht, dass der Satz ein stark positives Sentiment aufweist.




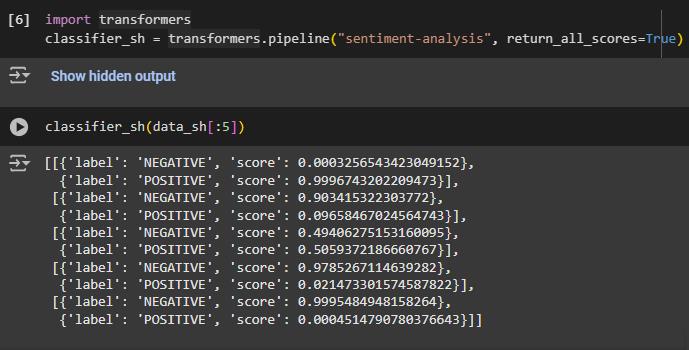
Wir können die Textplots für die Modellvorhersage zu anderen Kommentaren sehen, indem wir den ersten Parameter ändern, der den Index angibt, an dem die Kommentare im Dataframe vorhanden sind.
Wenn Sie sehen möchten, wie diese Art von Transparenz auf Feature-Ebene zu einer vollständigen Governance auf Unternehmensebene skaliert wird durch Bewertung, Überwachung und Korrektur von KI-Ausgaben in der Produktion...
Um Textplots für mehrere Werte anzuzeigen, können wir einen Start- und Endpunkt festlegen, genau wie bei einem normalen Dataframe. Hier plotten wir die Modellvorhersagen der ersten fünf Kommentare mithilfe des Textplots.
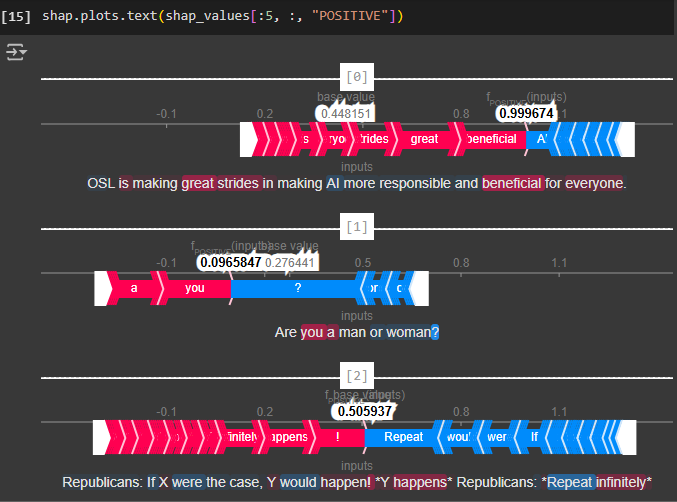
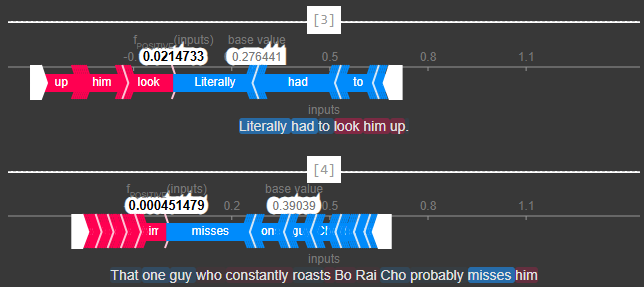
Unten sehen wir den SHAP-Wasserfalldiagramm, der einen von oben nach unten fließenden Wasserfall nachahmt. Der Plot beginnt beim Basiswert des Modells und zeigt dann, wie jedes Merkmal die Vorhersage für den spezifischen Kommentar nach oben oder unten in Richtung der endgültigen Vorhersage verschiebt.
Der Basiswert wird hier als E[f(x)] bezeichnet, was den Startpunkt des Wasserfalls darstellt.
f(x) repräsentiert den endgültigen Vorhersagewert des Modells für den spezifischen Kommentar.
Jeder Balken repräsentiert ein Merkmal im Kommentar und ist nach seinem Einfluss auf die Vorhersage geordnet, wobei die einflussreichsten oben stehen.
![]()
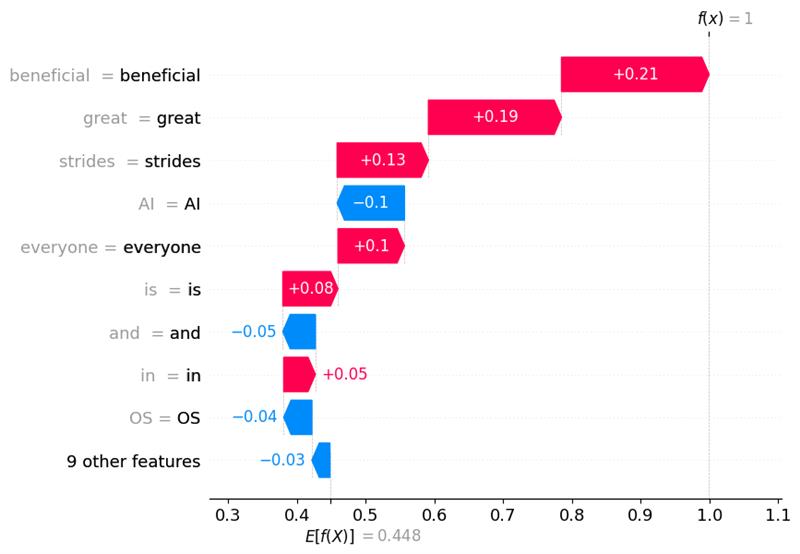
Das Obige ist ein Wasserfalldiagramm für die „POSITIVE“ Natur des Sentiments, wie im Code erwähnt. Auch hier sehen wir, dass Wörter wie „great (0.19)“ und „beneficial (0.21)“ zur positiven Natur des Sentiments beitragen, während Wörter wie „AI (-0.1)“ zur negativen Seite des Sentiments beitragen. „9 other features“ sind die Merkmale, die den geringsten Einfluss auf die Vorhersage des Modells in Bezug auf die positive Natur des Sentiments haben. Da f(x)=1 größer ist als E[f(X)]=0.45, zeigt dies, dass das Sentiment eine stark positive Natur hat.
Ähnlich ist für die „NEGATIVE“ Natur des Sentiments der Graph lediglich das Spiegelbild von „POSITIV“, und da f(x)=0 kleiner ist als E[f(X)]=0.55, zeigt dies, dass das Sentiment positiv ist.
![]()
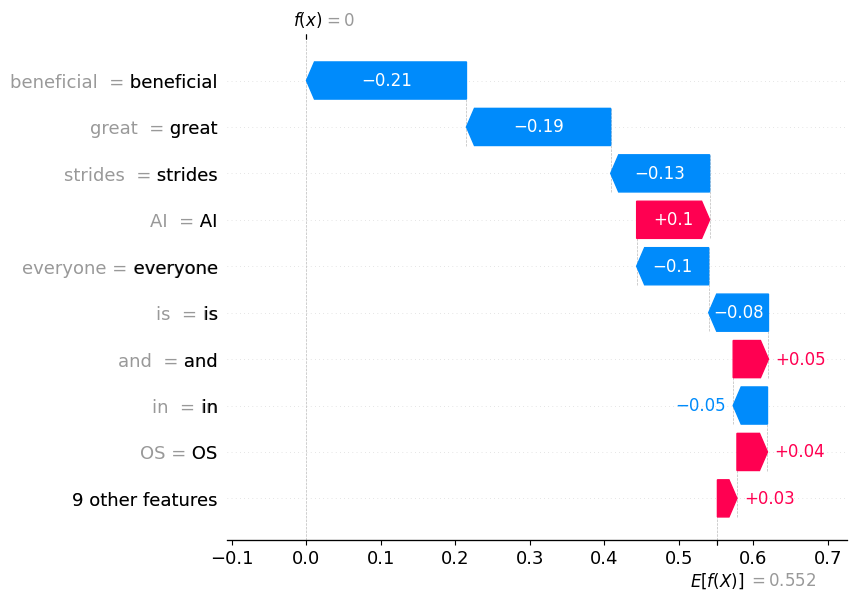
Um zu analysieren, wie das Modell seine Vorhersage für andere Kommentare erreicht hat, müssen wir lediglich den ersten Parameter ändern, nämlich den Index, an dem der Kommentar im Data Frame vorhanden ist, um den Wasserfalldiagramm für dieselbe Vorhersage zu sehen.
![]()
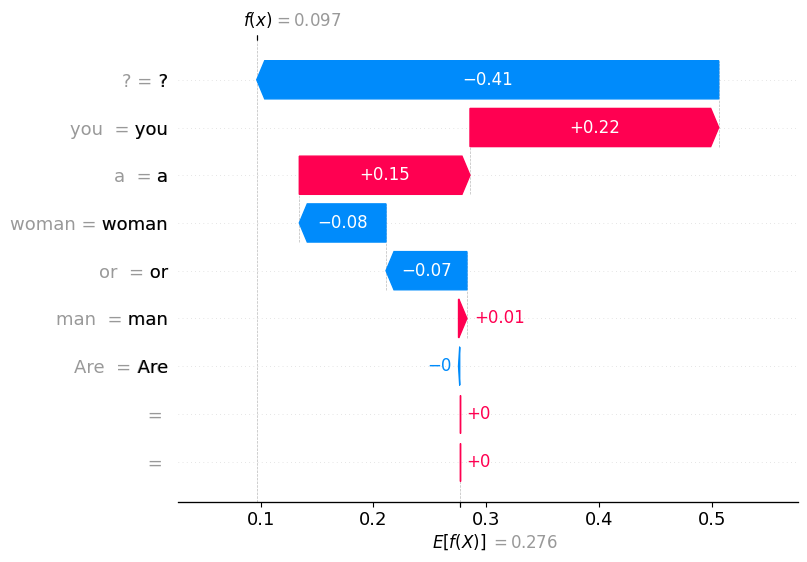
Insgesamt hilft uns der SHAP-Wasserfalldiagramm zu erkennen, warum das Modell eine bestimmte Vorhersage getroffen hat, und liefert Einblicke in die Merkmale, die die Sentiment-Entscheidungsfindung beeinflussen.
Lesen Sie auch:
1. Top Drupal-Module 2018 mit Künstlicher Intelligenz
2. E-Commerce und Datenanalyse: Steigern Sie Ihre Umsätze
3. Was ist ein Content-Management-System: Top 10 CMS für 2025
4. Was ist ein Headless CMS: Erklärt
Wichtige Erkenntnisse
1. SHAP (SHapley Additive exPlanation) ist eine effektive und beliebte Technik, um die Funktionsweise von Machine-Learning-Modellen zu verdeutlichen.
2. Ein Modell kann durch seine grundlegende Mathematik und Struktur erklärt werden, doch mit zunehmender Komplexität des Modells wird es schwieriger zu verstehen, wie es Entscheidungen trifft.
3. Der SHAP-Wasserfalldiagramm beginnt mit dem Basiswert des Modells und veranschaulicht, wie jedes Merkmal die Vorhersage beeinflusst, indem es diese entweder erhöht oder verringert, was zur endgültigen Vorhersage für den jeweiligen Kommentar führt.
4. Der SHAP-Wasserfalldiagramm zeigt uns die Gründe für die Vorhersage des Modells und gibt uns einen klareren Einblick in die Merkmale, die die Sentiment-Entscheidung beeinflussen.
5. Da die Technologie immer komplexer wird und LLMs in der KI eingeführt werden, wird das Verständnis der Modellergebnisse schwieriger.

Newsletter abonnieren
Open-Source-Technologie begeistert Sie? Bleiben Sie mit Projekten auf dem Laufenden, die einen Unterschied machen.



