
Ein umfassender Leitfaden zu Microservices
Microservices haben die Anwendungsentwicklung im Sturm erobert. Sie haben Unternehmen durch zahlreiche Vorteile maßgeblich beeinflusst. Die Arbeit mit Microservices ist eher eine Kunst als eine Wissenschaft. Anwendungsentwickler:innen fällt es oft schwer, die Feinheiten und die Umsetzung einer gut konzipierten Microservice-Architektur zu erfassen.
Wir haben Microservices bereits in vielen unserer früheren Artikel erwähnt. Diesmal stellen wir Ihnen einen umfassenden Leitfaden für Microservices vor. Dieser Leitfaden wird all jenen als hilfreiche Ressource dienen, die diese containerbasierte Architektur im Detail verstehen möchten.
Die Philosophie hinter Microservices – Monolithen und ihre Nachteile
Eine monolithische Anwendung ist eine einzige, bereitstellbare Einheit, die verschiedene Komponenten umfasst, welche zu einer einzigen funktionsfähigen Plattform gekapselt sind. Eine Datenbank, eine clientseitige Benutzeroberflächenschicht und serverseitige Anwendungen sind die Komponenten einer monolithischen Anwendung. Jeder kennt die Programmiersprache Java, die als eigenständiges Paket in verschiedenen Formaten wie EAR, WAR, JAR vorliegt und als einzelne Einheit auf dem Anwendungsserver bereitgestellt wird.
Die folgende Abbildung zeigt die grundlegende Struktur einer monolithischen Anwendung.
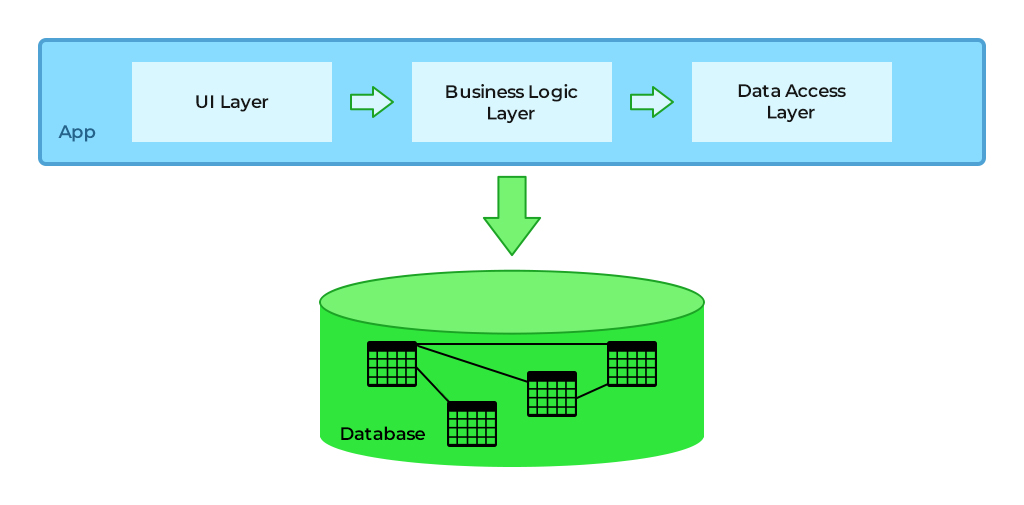
Grundsätzlich werden objektorientierte Prinzipien für den Aufbau monolithischer Anwendungen verwendet, die die Entwicklungs-, Debugging-, Test- und Bereitstellungsprozesse vereinfachen. Dies funktioniert gut, wenn sich die Anwendungen in ihren Anfangsphasen befinden und die Struktur vereinfacht ist. Mit zunehmender Größe der Anwendung nehmen Klassenhierarchien und Interdependenzen zwischen Komponenten zu, was zu einer komplexen Anwendung führt.
Die zunehmende Komplexität macht monolithische Anwendungen zu einer ungünstigen Wahl für die Cloud-Umgebung. Die folgenden Punkte untermauern dies.
- Fehlerisolation ist schwierig: Wie bereits erwähnt, gibt es als einzelne bereitstellbare Einheit keine physische Trennung zwischen den verschiedenen Funktionsbereichen (z. B. ist eine einzelne Funktion von der Funktionalität einer anderen Funktion abhängig) eines monolithischen Systems. Daher kann keine einzelne Veröffentlichung garantieren, dass sie nur den Bereich betrifft, für den sie bestimmt ist. Unerwünschte Nebenwirkungen sind bei einer monolithischen Anwendung daher immer eine Möglichkeit.
- Erweiterung erfordert mehr Ressourcen: Selbst für die Hinzufügung einer kleinen Funktion oder Funktionalität benötigt eine monolithische Anwendung zusätzliche Ressourcen. In den meisten Fällen erfolgt die Erweiterung oder Skalierung einer monolithischen Anwendung durch die gleichzeitige Bereitstellung mehrerer Instanzen der gesamten Anwendung. Dies führt zu einem erhöhten Gesamtverbrauch an Speicher- und Rechenressourcen. Darüber hinaus verschlimmert die Hinzufügung vieler Instanzen die Situation und kann auch zu Datenbank-Sperrproblemen führen.
- Bereitstellung ist zeitaufwändig: Mit zunehmender Komplexität erfordern die Entwicklungs- und QA-Zyklen für eine monolithische Anwendung mehr Zeit als üblich. Auch häufige Änderungen zum Zeitpunkt der Bereitstellung sind für monolithische Anwendungen nicht empfehlenswert, da dies einen erneuten Anwendungs-Build, vollständige Regressionstests und eine erneute Bereitstellung der gesamten monolithischen Anwendung erfordert. Dieser gesamte Prozess ist sehr zeitaufwändig und zudem recht kompliziert in der Umsetzung.
- Einsatz immer gleicher Technologien: Die Tendenz einer monolithischen Anwendung, sich auf einen einzigen Technologie-Stack zu beziehen, birgt viele Hürden. Die Schichten einer monolithischen Anwendung sind durch In-Process-Aufrufe eng gekoppelt. Um den Informationsaustausch zu optimieren, wird derselbe Technologie-Stack verwendet, wodurch die Vorteile neuer und bestehender Technologie-Stacks nicht genutzt werden können.
Um die Probleme monolithischer Anwendungen zu lösen, entwickelten sich Microservices zu einem entscheidenden Upgrade, um den Return on Investment für Unternehmen, die in die Cloud migrieren, zu steigern.
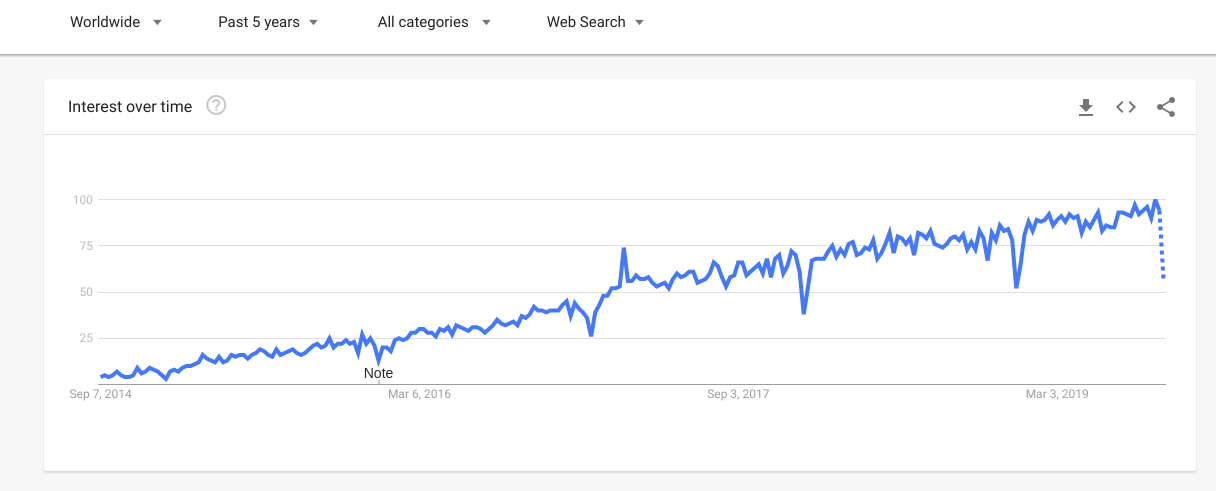
Bevor wir tiefer in die Details – das Was, Wie und Warum – der Microservices eintauchen, werfen wir einen Blick auf die steigende Popularität von Microservices in den letzten 5 Jahren, basierend auf der untenstehenden Google Trends Grafik.
Was sind Microservices?
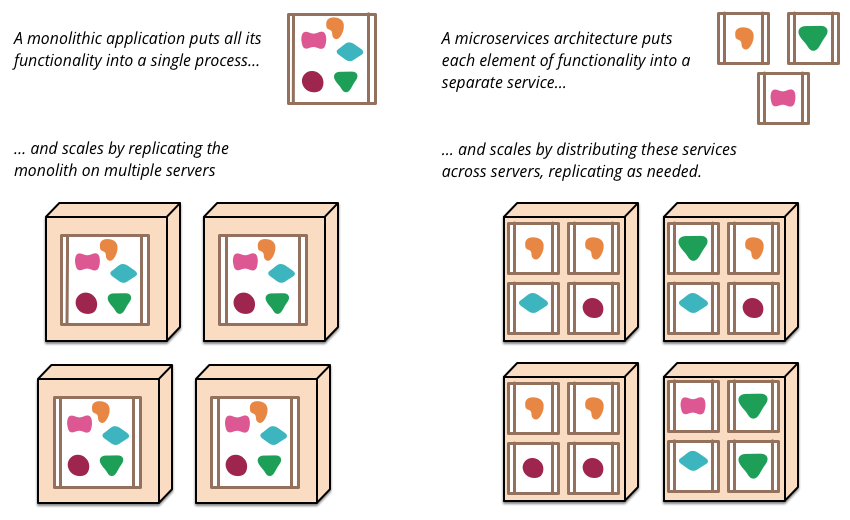
Microservices, das Schlagwort der modernen Softwareentwicklungsarchitektur, hat sich über Agile, DevOps und RESTful Services etabliert. Martin Fowler beschreibt Microservices als einen Ansatz, eine einzelne Anwendung als eine Suite kleiner, bereitstellbarer Dienste zu entwickeln.
Jeder Dienst läuft in einem eigenen Satz von Prozessen und kommuniziert über zahlreiche leichtgewichtige Protokolle (HTTP-Ressourcen-API). Die Dienste sind um eine Organisation herum, um Geschäftsfähigkeiten herum aufgebaut und werden mithilfe vollautomatisierter Bereitstellungsprozesse eingesetzt. Zusätzlich erfolgt eine dezentrale Steuerung und Verwaltung von Diensten, die in verschiedenen Programmiersprachen geschrieben sind und unterschiedliche Datenspeichertechnologien verwenden.
Dr. Peter Rogers verwendete den Begriff „Micro Web Services“ während einer Konferenz über Cloud Computing (2005). Bevor wir fortfahren, werfen wir einen Blick auf die Ereignisreihe, die die frühen Softwareentwicklungsmuster prägte und zur Entstehung von Microservices führte.
Die Evolution von Microservices
Um den allmählichen Aufstieg einer Microservice-Architektur zu verstehen, ist es unerlässlich, in der Zeit zurückzublicken und zu untersuchen, wie und wo alles begann. Die untenstehende Ereignisreihe wurde von IBM zusammengestellt, und wir haben sie auf der Grundlage der begleitenden Beobachtungen unterteilt.
Beobachtung 1: Nicht alles, was verteilt werden kann, sollte auch verteilt werden.
Anfang der 1980er Jahre kam es zur Einführung von Remote Procedure Calls (RPC) durch Sun Microsystems, die auf ONC RPC (Open Network Computing Remote Procedure Call) sowie auf den Prinzipien von DCE (Distributed Computing Environment, 1988) und CORBA (Common Object Request Broker Architecture, 1991) basierten. Das Fundament dieser Technologien war es, Remote-Aufrufe für Entwickler:innen transparent zu gestalten. Die großen, maschinenübergreifenden Systeme wurden entwickelt, um Verarbeitungs- und Speichererweiterungsprobleme beim Aufruf lokaler oder entfernter RPCs zu vermeiden.
Allmählich wurden die lokalen Adressräume mit der Verbesserung der Prozessoren größer. Eine wichtige Beobachtung ergab sich aus dieser großen Menge an DCE- und CORBA-Implementierungen: Wenn etwas verteilt werden kann, bedeutet das nicht, dass es auch verteilt werden sollte. Martin Fowler beschrieb dies später als Microservices, die um Geschäftsfähigkeiten herum organisiert sein sollten.
Als große Speicherbereiche zur Routine wurden, wurde die Systemleistung durch die schlechte Methodenverteilung beeinträchtigt. Früher führte der geringe Speicherplatz zu vielen „gesprächigen“ Schnittstellen. Doch Systeme mit den Vorteilen großer Speicherplatzverteilung übertrafen die Netzwerk-Overheads.
Beobachtung 2: Der Kollaps eines lokalen verteilten Aufrufs.
Um die Beobachtung zu den Speicherbereichen zu adressieren, entstand das erste Fassadenmuster. Es basierte auf dem Session-Fassaden-Ansatz. Das Hauptziel dieses Musters war es, eine strukturierte Schnittstelle zu schaffen, um den Informations- oder Datenaustausch zu optimieren. Das Muster wurde in verteilten Systemen und an den groben Schnittstellen ganzer Subsysteme angewendet, wodurch nur jene freigelegt wurden, die zur Verteilung verfügbar waren. Die gesamte Idee eines Fassadenmusters definiert eine spezifische externe API für ein System oder Subsystem, die geschäftsorientiert sein sollte.
Eine API, die Abkürzung für Application Programming Interface, ist ein Framework, das die Kommunikation zwischen zwei Anwendungen erleichtert. APIs ermöglichen es Entwickler:innen, entweder auf Anwendungsdaten zuzugreifen oder deren Funktionalität zu nutzen. Technisch gesehen sendet eine API Daten mittels HTTP-Anfragen. Die textuelle Antwort wird im JSON-Format zurückgegeben. REST, SOAP, GraphQL, gRPC sind einige der API-Designstile. OpenAPI, RAML oder AsyncAPI sind weitere Spezifikationsformate, die zur Definition von API-Interaktionen in menschen- und maschinenlesbaren Formaten verwendet werden.
Die ersten Session-Fassaden wurden mit Enterprise JavaBeans (EJBs) implementiert, was gut funktionierte, wenn ein Benutzer mit Java arbeitete, aber für andere Sprachen traten Komplikationen auf, da das Debugging umständlich wurde. Dieser Mangel an Kompatibilität führte zur Entstehung eines neuen Ansatzes namens Service Oriented Architecture (SOA), ursprünglich Simple Object Access Protocol (SOAP). Eine serviceorientierte Architektur kann als wiederverwendbare und synchron kommunizierende Dienste und APIs definiert werden. Diese erleichtern den beschleunigten Anwendungsentwicklungsprozess und die einfache Datenintegration aus anderen Systemen.
Bei SOAP ging es ausschließlich um die Aufrufe von Objektmethoden über HTTP und es erleichterte die Protokollierung und das Debugging von textbasierten Netzwerkaufrufen. SOAP förderte die heterogene Interoperabilität, scheiterte jedoch bei der Handhabung von Methoden, die über einfache Methodenaufrufe hinausgingen, wie Fehlerbehandlung, Transaktionsunterstützung, Sicherheit und digitale Signaturen. Dies brachte eine neue Erkenntnis hervor: Der Versuch, ein verteiltes System als lokales System zu betrachten, war schon immer eine Sackgasse. Martin Fowler bezeichnete dies später bei der Beschreibung der Microservices-Architektur als „Smart Endpoints und Dumb Pipes“.
Beobachtung 3: Eigenständige Laufzeitumgebungen.
Allmählich wurden die prozeduralen, geschichteten Konzepte von SOAP und den WS-*-Standards durch Representational State Transfer (REST) abgelöst. REST konzentrierte sich auf die Verwendung der HTTP-Verben, wie sie zur Erstellung, zum Lesen, Löschen und Aktualisieren von Semantiken spezifiziert wurden. Zudem definierte es eine Methode zur Spezifikation eindeutiger Entitätsnamen, genannt Uniform Resource Identifier (URI).
Gleichzeitig erfolgte die Ablehnung eines weiteren Erbes der Java-Plattform, der Java Enterprise Edition (JEE) und SOA. Zum Zeitpunkt ihrer Einführung führte JEE zahlreiche Unternehmen dazu, die Idee zu übernehmen, einen Anwendungsserver als Host für eine Reihe verschiedener Anwendungen zu nutzen. Eine einzige Betriebsgruppe kontrollierte, überwachte und wartete eine Gruppe identischer Anwendungsserver, meist von Oracle oder IBM, um die Bereitstellung verschiedener Abteilungsanwendungen auf dieser Gruppe durchzuführen und so die gesamten Betriebskosten zu senken.
Die Anwendungsentwickler:innen hatten Schwierigkeiten, mit großen Entwicklungs- und Testumgebungen zu arbeiten. Dies lag daran, dass die Umgebungen schwer zu erstellen waren und Betriebsteams für ihre Funktion benötigten. Es wurden Inkonsistenzen zwischen Anwendungsserverversionen, Patch-Levels, Anwendungsdaten und Softwareinstallationen zwischen den Umgebungen festgestellt. Die Open-Source-Anwendungsserver (Tomcat oder Glassfish) wurden von den Entwickler:innen bevorzugt, da sie kleiner und leichtgewichtige Anwendungsplattformen waren.
Gleichzeitig wirkte sich die Komplexität von JEE zugunsten der Spring-Plattform aus, da Techniken wie Inversion of Control und Dependency Injection üblich wurden. Die Entwicklungsteams stellten fest, dass sie durch eigene unabhängige Laufzeitumgebungen im Vorteil waren, was zu einer dezentralen Governance und Datenverwaltung führte. Die so entstandene Ereignisreihe legte eine starke Grundlage für die Einführung von Microservices in Unternehmen.

Wie sich monolithische und Microservices-Architekturen unterscheiden
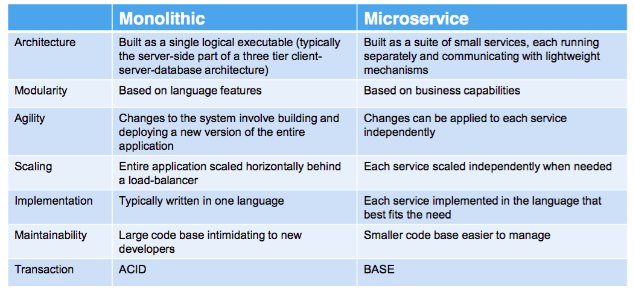
Merkmale von Microservices
#1 Komponentisierung verbessert die Skalierbarkeit
Bei Microservices werden Anwendungen durch die Aufteilung von Diensten in separate Komponenten erstellt. Dies ermöglicht reibungslose Änderungen, Entwicklung und Bereitstellung eines Dienstes eigenständig. Zudem ist der geringe Abhängigkeitsgrad der Microservices ein Vorteil für Entwickler:innen, da Änderungen, erneute Bereitstellungen oder Skalierungen an spezifischen Teilen der Anwendung vorgenommen werden können, anstatt am gesamten Code. So können Leistung und Verfügbarkeit geschäftskritischer Dienste durch die Bereitstellung auf mehreren Servern verbessert werden, ohne die Leistung anderer Dienste zu beeinträchtigen.
#2 Logische Funktionsgrenzen und erhöhte Ausfallsicherheit
Wie bereits erwähnt, ist bei Microservices die gesamte Anwendung dezentralisiert und in Dienste entkoppelt. Dies legt die Grenzen zwischen den Diensten fest und schafft ein Maß an Modularität, sodass Entwickler:innen wissen, wann und wo eine Änderung stattgefunden hat. Anders als bei monolithischen Architekturen wirkt sich eine Anpassung der Funktionalität eines Dienstes nicht auf andere Teile der Anwendung aus, und selbst wenn mehrere Teile des Systems ausfallen, bleibt dies von den Benutzer:innen unbemerkt.
#3 Ausfallsicher mit einfacherem Debugging und Testen
Anwendungen, die mit Microservices entwickelt wurden, sind intelligent genug, um mit Fehlern umzugehen. Wenn ein einzelner Dienst unter verschiedenen interagierenden Diensten ausfällt, wird der ausgefallene Dienst sauber isoliert.
Darüber hinaus können Fehler durch das kontinuierliche Monitoring der Microservices erkannt werden. Durch den kontinuierlichen Liefer- und Testprozess wird die Verteilung fehlerfreier Anwendungen beschleunigt.
#4 Verbesserter ROI und reduzierte TCO durch Ressourcenoptimierung
Bei Microservices arbeiten mehrere Teams an unabhängigen Diensten, was eine schnelle Bereitstellung der Anwendung ermöglicht. Es wird ein Continuous-Delivery-Modell verfolgt, das es Entwickler-, Betriebs- und Testteams ermöglicht, gleichzeitig an einem einzigen Dienst zu arbeiten. Die Entwicklungszeit wird durch einen Großteil der Code-Wiederverwendung reduziert. Auch das Testen und Debugging einer Anwendung wird einfach und sofort möglich.
Darüber hinaus sind für den Betrieb dieser entkoppelten Dienste keine teuren Maschinen oder Systeme erforderlich; grundlegende x86-Maschinen erledigen die Arbeit. Diese Ressourcenoptimierung sowie die kontinuierliche Bereitstellung und das Deployment erhöhen die Effizienz von Microservices, reduzieren die Infrastrukturkosten und Ausfallzeiten und führen letztendlich zu einer schnellen Markteinführung der Anwendung.
#5 Flexible Werkzeugauswahl
Abhängigkeiten von einem einzigen Anbieter sind bei Microservices nicht gegeben. Stattdessen besteht die Flexibilität, ein Werkzeug je nach Aufgabe zu verwenden. Jeder Dienst kann sein eigenes Sprach-Framework oder Hilfsdienste verwenden, während er weiterhin mit den anderen Diensten in der Anwendung kommuniziert.
Wie die Kommunikation in Microservices abläuft
Die Grundidee der Inter-Service-Kommunikation besteht darin, dass zwei Microservices entweder über HTTP-Protokoll oder asynchrone Nachrichtenmuster miteinander kommunizieren. Die beiden Arten der Inter-Service-Kommunikation in Microservices werden im Folgenden beschrieben:
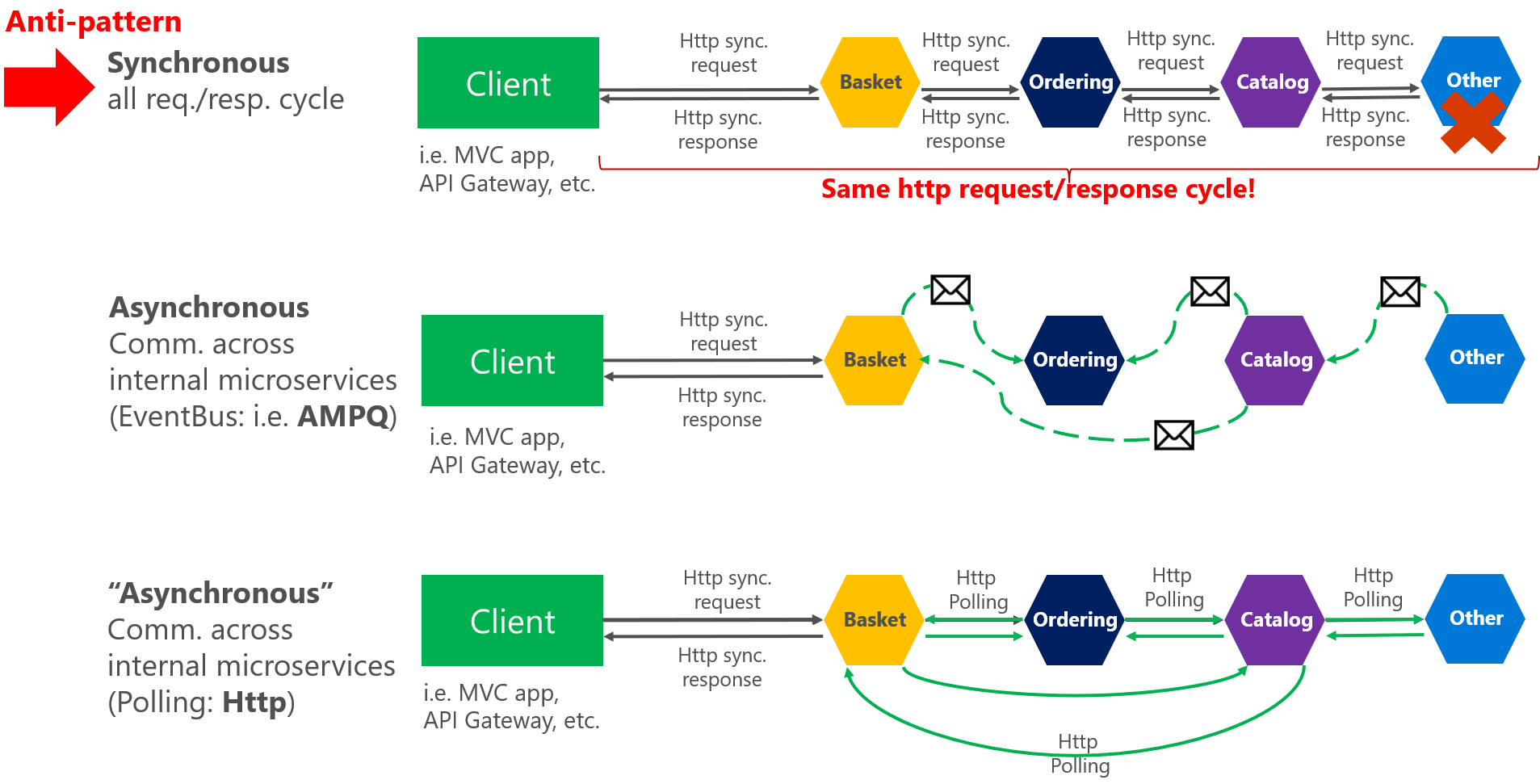
- Synchrone Kommunikation- Zwei Dienste kommunizieren über einen REST-Endpunkt mittels HTTP- oder HTTPS-Protokoll miteinander. Bei synchroner Kommunikation wartet der aufrufende Dienst, bis der aufgerufene Dienst antwortet.
- Asynchrone Kommunikation- Die Kommunikation erfolgt über asynchrones Messaging. Beim asynchronen Messaging muss der aufrufende Dienst nicht auf die Antwort des aufgerufenen Dienstes warten. Zuerst wird eine Antwort an den Benutzer zurückgegeben und dann die verbleibenden Anfragen verarbeitet. Apache Kafka, Apache ActiveMQ werden für die asynchrone Kommunikation in Microservices verwendet.
Überlegungen zum Aufbau einer Microservices-Architektur
Zunächst ist ein Bauplan oder eine Struktur für den erfolgreichen Aufbau einer Microservices-Architektur erforderlich. Um beispielsweise eine domänenbasierte Struktur zu erstellen, kann diese in die folgenden Elemente oder Vertikalen unterteilt werden:
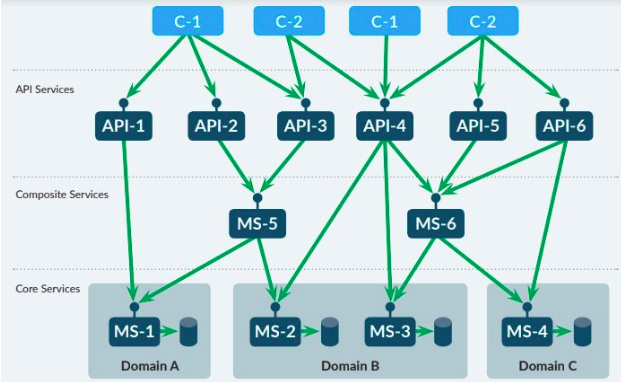
- Zentrale Dienste: Sie wenden die Geschäftsregeln und die weiteren Logiken an. Zudem wird die Konsistenz der Geschäftsdaten von einem zentralen Dienst verwaltet.
- Kompositdienste: Zum Zweck der Ausführung einer gemeinsamen oder ähnlichen Aufgabe und jeder Art von Informationssammlung aus verschiedenen zentralen Diensten übernehmen Kompositdienste die organisatorische Abwicklung der zentralen Dienste.
- API-Dienste: Ermöglichen es Dritten, kreative Anwendungen zu entwickeln, die die primäre Funktionalität in der Systemlandschaft nutzen.
Neben der Struktur muss vor der Skalierung der Microservices eine Zielarchitektur definiert werden. Der Grund dafür ist, eine Störung der IT-Landschaft zu verhindern, die zu deren Unterperformance führen könnte.
Was beim Umstieg auf Microservices zu beachten ist
Der Übergang von Monolithen zu Microservices geschieht nicht über Nacht. Adrian Cockcroft, ein Microservices-Evangelist und bekannt für die Einführung von Microservices bei Netflix, hat die folgenden Best Practices für die Gestaltung und Implementierung einer Microservices-Architektur innerhalb einer Organisation aufgeführt.
- Fokus auf die Steigerung der Geschäftskompetenz: Bei der Arbeit an Microservices wird den Teams empfohlen, Kenntnisse über vielfältige Anforderungen für spezifische Geschäftsfähigkeiten zu besitzen. Zum Beispiel die Genehmigung der Bestellung, der Versand zur Verwaltung der Produktlieferung. Zusätzlich sollten Dienste als unabhängige Produkte mit guter Dokumentation entwickelt werden, wobei jeder für eine einzelne Geschäftsfähigkeit verantwortlich ist.
- Ähnlicher Reifegrad für alle Codes: Der gesamte in Microservices geschriebene Code sollte denselben Reifegrad und dieselbe Stabilität aufweisen. Wenn Code für einen Microservice hinzugefügt oder umgeschrieben werden muss, ist der günstigste Ansatz, den bestehenden Microservice zu belassen und einen neuen Microservice für den neuen oder geänderten Code zu erstellen. Dies ermöglicht die iterative Freigabe und das Testen eines neuen Codes, bis dieser fehlerfrei und effizient ist.
- Kein einzelner Datenspeicher: Der Datenspeicher sollte gemäß den Anforderungen jedes Microservices-Teams ausgewählt werden. Eine einzige Datenbankquelle für jeden Microservice birgt einige unnötige Risiken, zum Beispiel wird sich eine Aktualisierung der Datenbank in jedem Dienst, der auf diese Datenbank zugreift, auswirken, unabhängig von ihrer Relevanz oder nicht.
- Container-Bereitstellung: Die Bereitstellung in Containern führt zur Nutzung eines einzigen Tools, das die Auslieferung eines Microservice erleichtert. Docker ist heutzutage der am häufigsten gewählte Container.
- Zustandslose Server: Server können je nach Anforderung oder bei jeder Art von Fehlfunktion ersetzt werden.
- Alles überwachen: Microservices bestehen aus einer Vielzahl beweglicher Teile, daher ist es unerlässlich, alles sorgfältig zu überwachen, wie z. B. Benachrichtigungen über Antwortzeiten, Dienstfehler und Dashboards. Splunk und AppDynamics sind eine Hilfe im Microservices-Messprozess.
Es besteht kein Zweifel, dass Microservices ein heißer Trend für die aktuelle Generation der Anwendungsentwicklung sind, aber sie bringen auch einige Nachteile mit sich.
Die Nachteile von Microservices
Below are listed some potential drawbacks associated with microservices.
- Zunehmende Komplikationen: Die Entwicklung verteilter Systeme ist komplex und wird mit der Verzögerung von Remote-Aufrufen allmählich zunehmen. Aufgrund der unabhängigen Dienste muss jede Anfrage sorgfältig behandelt werden, und auch die Kommunikation zwischen den Modulen erfordert besondere Sorgfalt. Darüber hinaus wird von den Entwickler:innen ein zusätzlicher Code angehängt, um Behinderungen zu vermeiden. Die Bereitstellung von Microservices kann umständlich sein und erfordert eine vollständige Koordination zwischen verschiedenen Microservices.
- Umständliches Datenmanagement: Mit der Präsenz mehrerer Datenbanken wird es ziemlich unübersichtlich, Transaktionen und die Verwaltung eines Datenbank-Speichers zu handhaben.
- Aufwändiges Testen: Die Abhängigkeit zwischen Diensten muss vor der Durchführung der Microservices-Tests bestätigt werden, d. h. robustes Monitoring und Testen sind unerlässlich.
Tools zur Verwaltung von Microservices
Die Suche nach den richtigen Tools ist unerlässlich, bevor eine Microservices-Anwendung erstellt wird. Eine Vielzahl von Open-Source- und kostenpflichtigen Tools ist verfügbar, die den Aufbau von Microservices unterstützen. Es wurde jedoch immer gesagt, dass die Microservices-Entwicklung mit den verfügbaren Open-Source-Tools ihre Stärken besonders ausspielt. Im Folgenden sind einige Tools für den Aufbau einer Microservices-Anwendung aufgeführt:
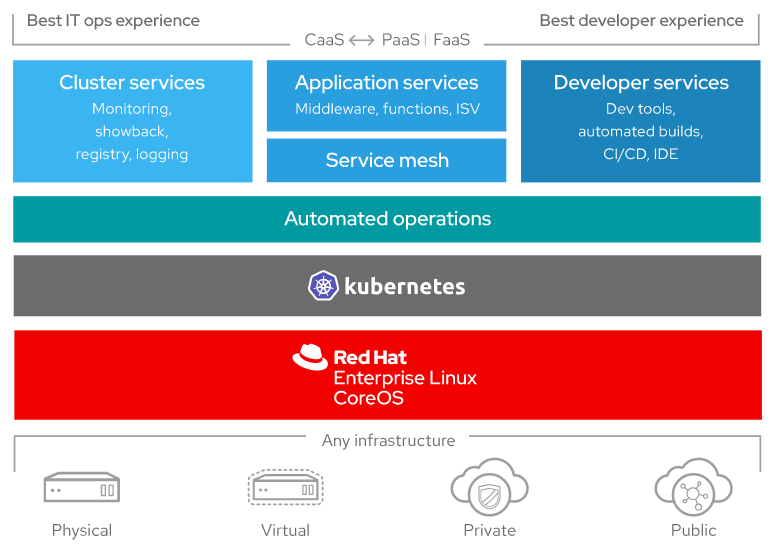
- Red Hat OpenShift – Red Hat OpenShift ist eine frei verteilte, vielseitige Container-Anwendungsplattform von Red Hat Inc. Eine Anwendung, die auf Kubernetes mit Docker-Containern basiert, wird weit verbreitet für die Entwicklung, Bereitstellung und Verwaltung von Anwendungen in Hybrid-, Cloud- und Unternehmensumgebungen eingesetzt. Das untenstehende Diagramm zeigt die Komponenten der OpenShift-Plattform.
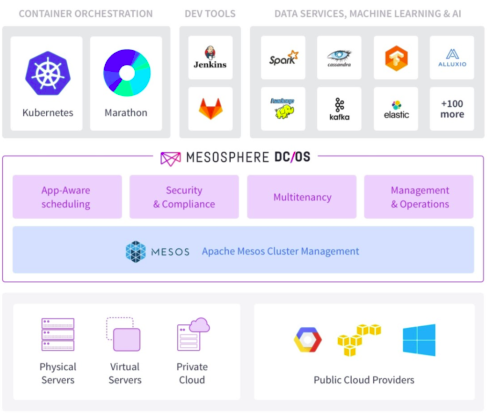
Mesosphere – Mesosphere ist ein verteiltes Computerbetriebssystem zur Verwaltung von Clustern. Die Container-Plattform basiert auf dem Open-Source-Kernel Apache Mesos und Mesospheres DC/OS (Data Center Operating System). Die robuste, flexible und plattformübergreifende Containerisierungsplattform führt intensive Aufgaben innerhalb eines Unternehmens aus. Das untenstehende Diagramm zeigt die Komponenten von Mesosphere.
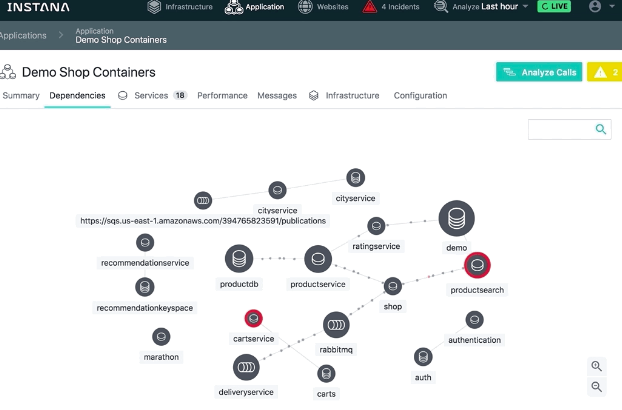
Instana – Das dynamische Application Performance Management System, das die automatische Überwachung ständig wechselnder moderner Anwendungen durchführt. Es wurde speziell für den Cloud-nativen Stack entwickelt und führt Infrastruktur- und Anwendungsleistungsüberwachung mit null Konfigurationsaufwand durch, wodurch der CI/CD-Zyklus (Continuous Integration/Continuous Deployment) beschleunigt wird. Das untenstehende Diagramm zeigt eine Instana-Abhängigkeitskarte für Demo-Shop-Container.
Entdecken Sie weitere Open-Source-Tools zur Verwaltung von Microservices-Anwendungen
Die Zukunft: Microservices werden Mainstream
Netflix, eBay, Twitter, PayPal und Amazon sind einige der großen Namen, die durch den Wechsel von einer monolithischen Architektur zu Microservices eine starke Marktpräsenz erlangt haben.
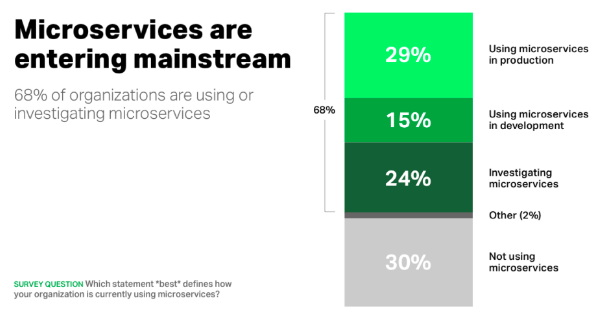
Eine Umfrage (2015) von Nginx mit der Frage „Welche Aussage beschreibt am besten, wie Ihr Unternehmen Microservices derzeit nutzt?“ besagt, dass fast 70 % der Organisationen Microservices entweder nutzen oder dazu forschen, wobei fast ein Drittel sie derzeit in der Produktion einsetzt.
Service Meshes, ereignisgesteuerte Architekturen, Container-native Sicherheit, GraphQL und Chaos Engineering waren die Microservices-Trends für das Jahr 2018. Der rasante Aufstieg von Microservices hat einige neue Trends in den Fokus gerückt. Im Folgenden werden die Prognosen für Microservices für 2019 genannt:
#1 Testautomatisierung
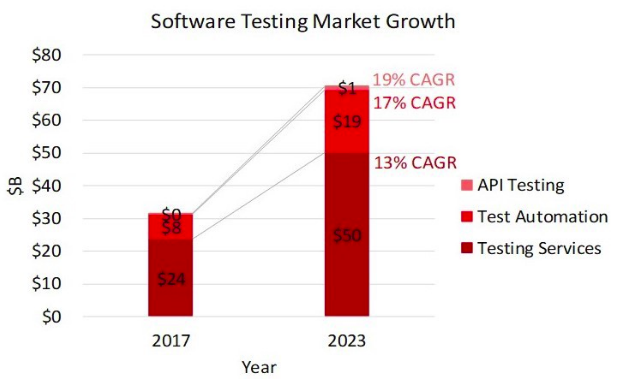
Tests werden durchgeführt, um den Zustand einer Anwendung zu überprüfen. Unternehmen streben stets nach Testlösungen, die Testläufe entwerfen und die Ergebnisse automatisch melden. Zudem sollte das Testen reibungslos verlaufen und Verbindungen zu CI-Systemen, die Echtzeitprüfung neuen Codes und das Hinzufügen von Kommentaren wie ein menschlicher Ingenieur ermöglichen. Künstliche Intelligenz wird viele Vorteile aus dem Softwaretesting ziehen, nämlich die Verbesserung von Produktivität, Kosten, Abdeckung und Genauigkeit. Die untenstehende Grafik zeigt das Wachstum des Softwaretest-Marktes von 2017 bis 2023.
#2 Continuous Deployment und erhöhte Produktivität durch Verifizierung
Beim Continuous Deployment wird der Code automatisch in die Produktionsumgebung bereitgestellt, nachdem er die Testphase erfolgreich durchlaufen hat. Eine Reihe von Designpraktiken wird im Continuous Deployment verwendet, um den Code in die Produktionsumgebung zu überführen.
Darüber hinaus werden mit Continuous Verification (CV) Ereignisdaten aus Logs und APMs gesammelt. Um die Funktionen zu identifizieren, die erfolgreiche und fehlgeschlagene Bereitstellungen verursacht haben.
#3 Fehlerbehebung durch Incident Response
Die komplexen verteilten Architekturen sind oft fragil. Die Site Reliability Engineers (SRE) sind verantwortlich für die Verfügbarkeit, Latenz, Leistung, Effizienz, das Änderungsmanagement, das Monitoring, die Notfallreaktion und die Kapazitätsplanung der Dienste. Die Incident Response ist eine entscheidende SRE-Aufgabe. Wenn ein Dienst ausfällt, kümmert sich ein Team mit unterschiedlichen Rollen um die Folgen der Ausfälle und verwaltet diese.
#4 Kosten sparen mit Cloud Service Expense Management (CSEM)
Die Verwaltung der Cloud-Kosten ist eine der wenigen Herausforderungen, die sowohl die Engineering- und IT-Teams als auch das gesamte Unternehmen betreffen. Cloud Service Expense Management überwacht und verwaltet die Cloud-Computing-Ausgaben und die Cloud-Ressourcen, die Unternehmen helfen, den besten Wert für ihre Geschäfte zu erzielen.
#5 Expansion von Machine Learning mit Kubernetes
Kubernetes wächst allmählich und wird Teil des Machine Learning (ML)-Stacks. Viele Unternehmen arbeiten daran, Kubernetes für ML- und analytische Workloads zu standardisieren.
Fazit
Microservices sind nicht neu. Sie haben ihre Präsenz bereits in Form von serviceorientierten Architekturen, Webdiensten usw. gezeigt. Als kleine, unabhängige Dienste, die zusammen eine Anwendung bildeten, entstanden Microservices, um monolithische Herausforderungen zu überwinden. Ein strukturbasierter Ansatz und die richtige Auswahl der Tools werden den Aufbau einer Microservice-Anwendung optimieren.
Wie sehen Sie das aus Ihrer Sicht? Teilen Sie Ihre Ansichten auf unseren Social-Media-Kanälen: Facebook, LinkedIn und Twitter.

Newsletter abonnieren
Open-Source-Technologie begeistert Sie? Bleiben Sie mit Projekten auf dem Laufenden, die einen Unterschied machen.



