
Doppelte Inhalte? Drupal eilt zur Hilfe!
Uns wird schon in jungen Jahren gesagt, dass niemand so ist wie wir. Wir sind etwas Besonderes. Aber was, wenn das nicht stimmt? Es gibt viele moderne Beweise dafür, dass wir alle mindestens einen Doppelgänger in diesem großen, weiten Kosmos haben. Wenn also die Schöpfer des Universums die Tendenz haben, menschliche Körper zu duplizieren, würden die Menschen selbst dieses Rennen aufgeben?
Etwa 25-30 % der Inhalte im Web sind doppelt vorhanden!
Der springende Punkt hier war, Ihre Aufmerksamkeit auf die Welt der Webseiten und die Bedeutung identischer Inhalte zu lenken, die auf mehr als einer Webseite erscheinen, mit anderen Worten: Doppelter Inhalt.
Doppelter Inhalt kann jedem jederzeit passieren.

Matt Cutts, Googles Leiter der Such-Spam-Abteilung, sagt, dass etwa 25-30 % der Inhalte im Web doppelt vorhanden sind. Leider ist sich die Mehrheit der Menschen dessen nicht einmal bewusst.
Das Ergebnis? Schadet Ihrem eigenen SERP, da Google doppelte Inhalte bestraft. Wer möchte das schon, oder? Daher ist die Beseitigung von Duplikaten eine wichtige Aktivität für die Gesundheit der Website.
Wie macht man das? Bevor ich auf die Lösungen zur Beseitigung von doppeltem Inhalt eingehe, werfen wir einen Blick darauf, was genau "doppelter Inhalt" ist.
Doppelter Inhalt
Doppelter Inhalt bezieht sich auf ähnliche Inhalte, die an mehreren Stellen (URLs) im Web erscheinen, so dass Suchmaschinen keine Ahnung haben, welche Webseiten in den Suchergebnissen angezeigt werden sollen. Wenn doppelter Inhalt vorhanden ist, erleiden Website-Betreiber einen enormen Rückgang ihres Rankings und verlieren schnell Traffic.
Aus einer breiten Perspektive betrachtet, betrifft dies sowohl die Suchmaschinen als auch die Website-Betreiber. Hier ist, wie es funktioniert:
Für Suchmaschinen
- Doppelter Inhalt kann ein Hindernis für die Suchmaschinen darstellen. Sie haben keine Ahnung, welche Version in die Indizes aufgenommen/ausgeschlossen werden soll.
- Suchmaschinen haben keine Ahnung, ob sie die Link-Metriken (Urheberschaft, Vertrauen, Link-Equity usw.) auf eine einzelne Seite oder auf mehrere Seiten lenken sollen.
Sie verstehen nicht, welche Version für das Ergebnis gerankt werden soll.
Für Website-Betreiber
- Die Suchmaschine würde selten mehrere Versionen desselben Inhalts anzeigen, um die beste Sucherfahrung zu bieten, und ist daher gezwungen, die Version auszuwählen, die am wahrscheinlichsten das beste Ergebnis ist. Dies schwächt die Sichtbarkeit jeder Webseite.
- Da auch andere Websites zwischen den Duplikaten wählen müssen, wird die Link-Equity weiter verwässert. Anstatt dass mehrere Links auf einen einzigen Inhalt verweisen, verweisen sie auf viele Teile und verteilen die Link-Equity auf die Duplikate. Da alle eingehenden Links den Ranking-Faktor darstellen, kann dies die Sichtbarkeit des Inhalts in der Suche beeinträchtigen.
Ergebnis: Der Inhalt erreicht nicht die Sichtbarkeit in der Suche

Warum passiert das?
Eine der häufigsten Fragen zu doppeltem Inhalt ist, warum er überhaupt auftritt.
Es kann vorkommen, dass der Benutzer die vorhandene Seite unbeabsichtigt nicht kopiert hat und dennoch damit konfrontiert wird.
Was erzeugt ihn also und woher kommt er?
Doppelter Inhalt entsteht, wenn mehrere Versionen einer einzelnen Seite erstellt werden. Dies geschieht, wenn die Seite in jedem Kontrast identisch aussieht, die URL jedoch etwas anders sein kann. Zum Beispiel

Dennoch gibt es zahlreiche Gründe, warum doppelter Inhalt an die Tür eines Website-Betreibers klopft. Werfen wir einen Blick auf einige weitere.
Arten von doppeltem Inhalt
1. Abgeschriebener Inhalt
Abgeschriebener Inhalt wird als ein nicht originelles Stück Inhalt auf einer bestimmten Website bezeichnet, das ohne Erlaubnis von einer anderen Website kopiert oder dupliziert wurde. Google unterscheidet nicht immer zwischen dem Original und dem kopierten Inhalt, es ist die Aufgabe des Website-Betreibers, auf Scraper zu achten.

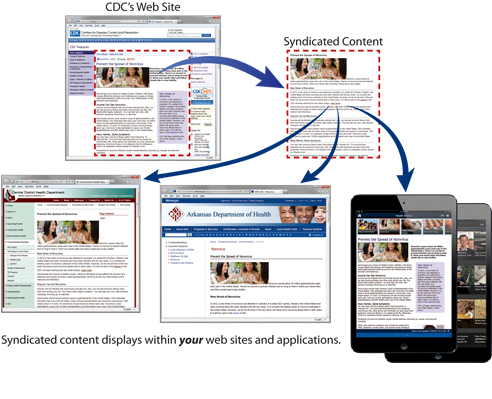
2. Syndizierter Inhalt
Diese Art von Inhalt wird mit Genehmigung des ursprünglichen Autors auf einer anderen Website erneut veröffentlicht, d. h. Sie pushen Ihren Beitrag (sei es ein Artikel, ein Blog-Beitrag, ein Video oder ein anderer webbasierter Inhalt) an Dritte, die ihn auf ihrer Website erneut veröffentlichen.
Sie könnten sagen, dass dies der legitime Weg sein sollte, um den Inhalt in die Augen des Publikums zu bringen, aber es sollte beachtet werden, wenn ich dies sage - es ist wichtig, Richtlinien für die Verlage festzulegen. Die Verlage können in diesem Fall das Canonical-Tag für den Artikel wählen, um die ursprüngliche Quelle der Daten anzugeben.
3. HTTP- und HTTPs-Seiten
Oh ja, das muss eines der häufigsten Duplizierungsprobleme sein. Identische URLs auf der Website entstehen, wenn der Wechsel von HTTP zu HTTPS nicht mit der erforderlichen Aufmerksamkeit für den Prozess implementiert wird. Mit anderen Worten, dieses Szenario tritt ein, wenn:
Ein Teil der Website ist HTTPs und verwendet URLs
Es ist immer sicher, eine einzelne Seite oder ein einzelnes Verzeichnis auf einer HTTP-Site zu verwenden. Sie sollten jedoch bedenken, dass diese Seiten interne Links haben, die eher auf relative als auf absolute URLs verweisen.
Relative URL: /use-drupal-intelligent-content-tools-module
Absolute URL: https://opensenselabs.com/blog/tech/use-drupal-intelligent-content-tools-module
Es sollte auch beachtet werden, dass relative URLs keine Protokollinformationen enthalten, sondern ein ähnliches Protokoll wie die übergeordnete Seite verwenden, auf der sie sich befinden. Wenn der Such-Bot einen internen Link findet, entscheidet er sich, ihm zu folgen. Er könnte das Crawling fortsetzen, indem er weiteren relativen internen Links folgt, oder er könnte sogar die gesamte Website crawlen und somit die beiden völlig identischen Versionen der Webseite indizieren.
Die Website wurde auf HTTPs umgestellt, aber die HTTP-Version ist weiterhin verfügbar
Dies geschieht, wenn es Backlinks von einer anderen Website gibt, die auf die HTTP-Seite verweisen, oder wenn einige der internen Links auf der Website noch das Protokoll enthalten. Die nicht sicheren Seiten leiten nicht auf die sicheren Seiten um.

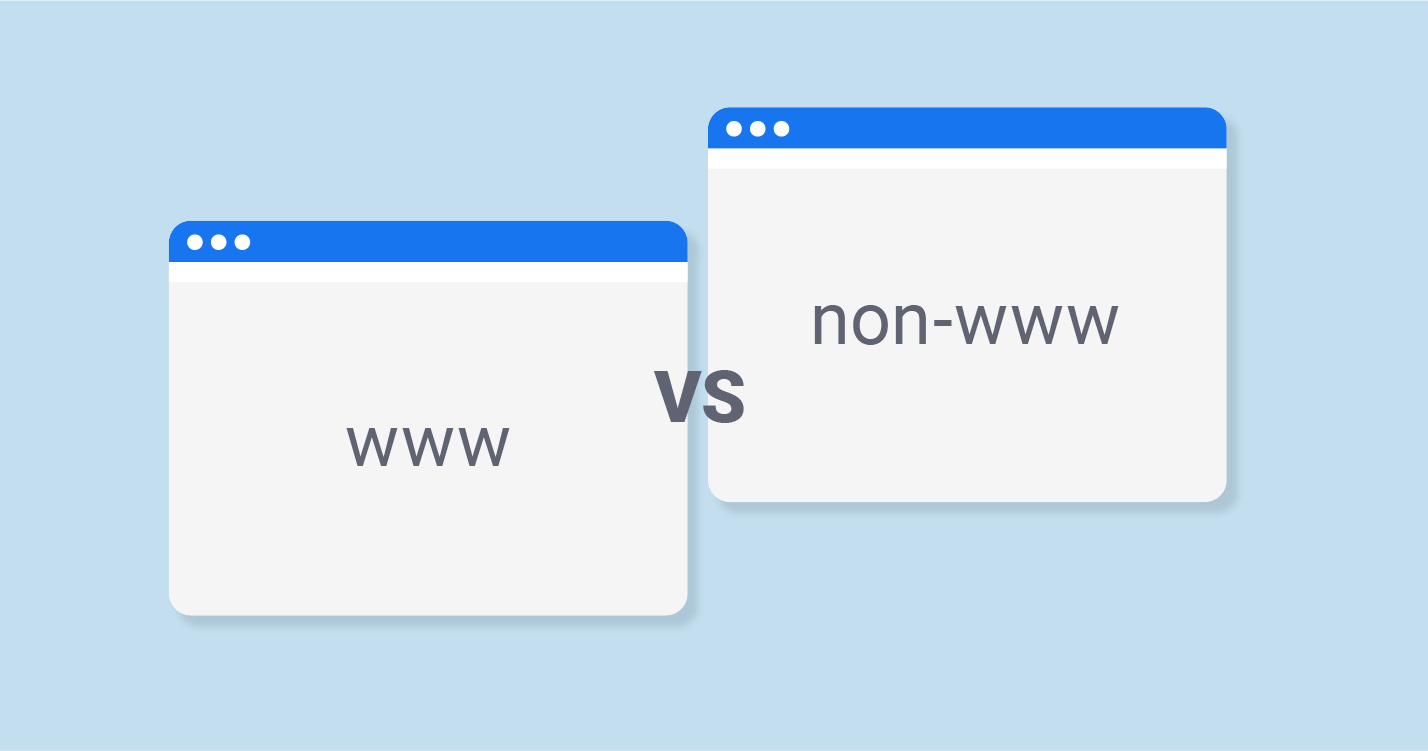
4. WWW- und Nicht-WWW-Seiten
Dies ist einer der ältesten Gründe für doppelte Inhalte, wenn die Website sowohl mit www als auch ohne www verfügbar ist. Wenn www. vor einer Website steht, erscheint sie als Hostname, der vielseitig mit DNS bedient werden kann. Dies schränkt die Cookies ein, wenn mehrere Subdomains verwendet werden, und mehr. Während Nicht-WWW-Domains auch als Naked Domains bezeichnet werden, haben sie keinen technischen Vorteil.
Wenn beide Versionen der Website im Web verfügbar sind, kann Google nicht erkennen, welche die Originalversion ist, und kennzeichnet daher beide als doppelten Inhalt.
5. Ähnlicher Inhalt
Wenn Leute die Duplizierung von Inhalten angeben, implizieren sie oft das Szenario, in dem es eine vollständige Identifizierung von identischem Inhalt gibt. Daher fällt das Stück sehr ähnlicher Inhalt für Google unter die Definition von doppeltem Inhalt. Es gibt Zeiten, in denen eine bestimmte Website die exakt gleichen Daten von einer anderen Website kopiert und unter die Definition von doppeltem Inhalt fällt. Dies kann häufig bei E-Commerce-Websites vorkommen, die ähnliche Produktbeschreibungen haben, die sich nur in wenigen Abschnitten unterscheiden.
Wie behebe ich Probleme mit doppeltem Inhalt mit Drupal?
Es ist wichtig, dass das CMS, das Sie verwenden, den Unterschied zwischen dem Inhalt, der unter Duplizität leidet, und dem Inhalt, der original ist, kennt. Drupal ist ein solches CMS, das diese Aufgabe recht gut erfüllt.
Es gibt ein paar Module, die den Websites helfen, die Originalität zu bewahren, ohne das Ranking und den Traffic der Webseiten zu beeinträchtigen.
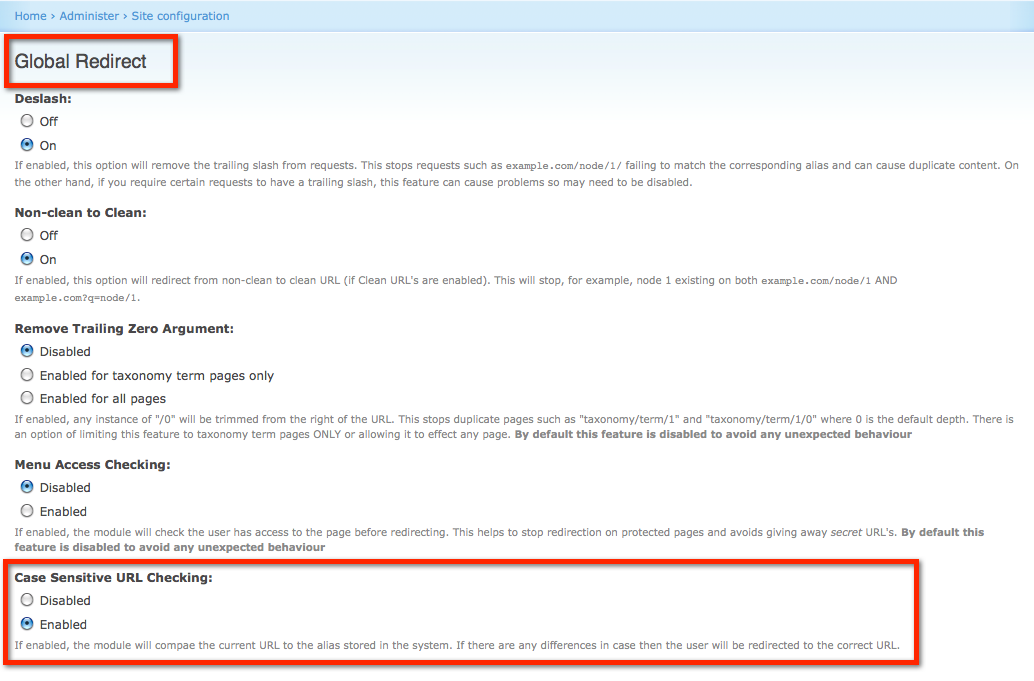
1. Global Redirect Module
Eines der Hauptmodule, das im Drupal SEO Checklist Module enthalten ist und für die Drupal SEO-Performance sehr empfohlen wird, ist das Global Redirect Module. Dies verhindert, dass Inhalte auf mehreren URLs angezeigt werden, wenn das Pfadmodul aktiviert ist. Die Anzeige von doppeltem Inhalt auf mehreren URLs kann zu einem Verlust des Suchmaschinen-Site-Rankings führen. So helfen Sie den Websites mit:
- Überprüfung der aktuellen URLs und führt 301-Weiterleitungen darauf durch, wenn sie nicht verwendet werden.
- Überprüft die aktuelle URL auf nachgestellte Schrägstriche, entfernt sie, falls vorhanden, und wiederholt die Überprüfung 1 mit der neuen Anfrage.
- Überprüft, ob die aktuelle URL mit der Startseite der Website übereinstimmt, und leitet darauf um, wenn eine Übereinstimmung vorliegt.
- Überprüft, ob die Funktion "Saubere URLs" aktiviert ist, und prüft dann, ob auf die aktuelle URL mit der sauberen Methode zugegriffen wird.
- Überprüft den Zugriff auf die URL. Wenn der Benutzer keinen Zugriff auf den Pfad hat, werden keine Weiterleitungen durchgeführt.
2) PathAuto
Drupal bietet dem Benutzer mit Hilfe von PathAuto inhaltsfreundliche URLs und generiert automatisch Pfade für verschiedene Inhalte. Einfach ausgedrückt, es ermöglicht Ihnen, von einem Pfad zu einem anderen Pfad oder einer externen URL umzuleiten, wobei Sie einen beliebigen HTTP-Weiterleitungsstatus verwenden können. Dies ist wichtig, wenn Sie das URL-Schema aus irgendeinem Grund ersetzen möchten und Sie nicht alle vorhandenen Links (Suchmaschinen, Benutzer-Lesezeichen usw.) zerstören möchten. Mit anderen Worten, das Pathauto-Modul erstellt automatisch URL-/Pfad-Aliase für verschiedene Arten von Inhalten (Nodes, Taxonomie-Begriffe, Benutzer), ohne den Benutzer aufzufordern, den Pfad-Alias manuell anzugeben.
Es sollte beachtet werden, dass die Unterstützung für mehrsprachige URL-Aliase noch instabil ist und vor der Verwendung in der Produktion getestet werden sollte.
3) Intelligente Content-Tools
Das Modul Intelligent Content Tools hilft Ihnen, den Inhalt zu personalisieren und bietet Ihnen 3 Funktionen:
1. Auto-Tagging
2. Zusammenfassung des Textes
3. Überprüfung auf doppelten Inhalt
Dieses Modul behebt die plagiierten Inhalte, und während die Anzahl der auf dem Markt verfügbaren Plagiatprüfer hoch ist, benachrichtigt Sie das Modul, wenn auf der Website doppelter Inhalt verfügbar ist. Es ist ein intelligentes Agentenmodul, das auf Natural Language Processing basiert. Es ist ein wertvolles Werkzeug für einen Website-Designer und Content-Editor.
Es sollte berücksichtigt werden, dass dieses Projekt nicht von der Sicherheitsrichtlinie abgedeckt ist.
4) Taxonomy Unique
Das Taxonomy Unique Modul verhindert das Speichern eines Taxonomie-Begriffs. Das heißt, wenn ein Begriff mit dem gleichen Namen im gleichen Vokabular existiert, kann der Benutzer ihn für jedes Vokabular einzeln konfigurieren und dann benutzerdefinierte Fehlermeldungen festlegen, wenn ein Duplikat gefunden wird. Es bietet den Benutzern auch
Eine Zusicherung, dass die Begriffsnamen eindeutig sind
- Es wird individuell für das Vokabular konfiguriert
- Legen Sie einen benutzerdefinierten Fehler fest, wenn die Duplikate gefunden werden.
5) Suggest Similar Titles
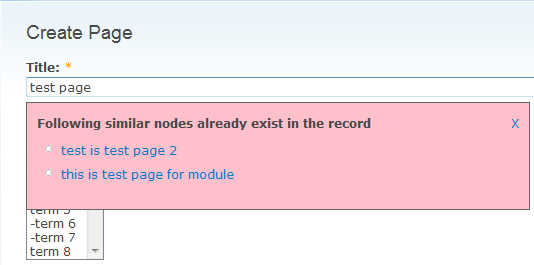
Das Modul Suggest Similar Titles vermeidet die Duplizierung der Titel für alle Arten von Inhalten. Dieses Modul gleicht die Node-Titel desselben Inhaltstyps ab und rät Ihnen, dass ein Titel mit diesem Titel übereinstimmt, der bereits in der Datenbank vorhanden ist. Dies hilft dem Administrator/Benutzer, die Duplizierung von Inhalten auf der Website zu vermeiden. Es bietet auch eine Einstellungsseite, auf der die folgenden Einstellungen vorgenommen werden können:-
Qualifizierung dieser Funktion für jeden Inhaltstyp
- Der Benutzer kann ignorierte Schlüsselwörter im Titelvergleich eingeben
- Sie können auch eine maximale Anzahl von Titeln auswählen, die als Vorschlag angezeigt werden sollen
- Die Wahl, ob dieses Modul Node-Berechtigungen berücksichtigen soll, bevor es den Node-Titel als Vorschlag anzeigt, kann erfolgen.
- Der Benutzer kann den Prozentsatz eingeben, wie genau das System den Titel vergleichen soll. Wenn Sie beispielsweise 75 eingeben, wird mindestens ein 75% übereinstimmender Titel als verwandt betrachtet
Dieses Modul verfügt über eine Vorlagendatei, um den vorgeschlagenen Inhalt gemäß den Anforderungen zu gestalten.
Fazit
Ja, es ist schwierig und hart, eine Website zu erstellen, die zu 100 Prozent frei von Duplikaten ist. Der wesentliche Aspekt ist, sicherzustellen, dass nicht ganze Seiten oder eine ganze Reihe von Seiten von einer Website zur nächsten dupliziert werden.
Aber wie wir sagen - "Alte Gewohnheiten sterben schwer", es kann immer noch Chancen geben, wo Sie in diese unglückliche Handlung verwickelt sind, und dies ist, wenn Drupal Ihr Retter ist. Bei OpenSense Labs begrüßen wir das Konzept von doppeltem, freiem Inhalt. Kontaktieren Sie uns unter [email protected], um mehr über die besten Möglichkeiten zur Beseitigung von doppeltem Inhalt zu erfahren.

Newsletter abonnieren
Open-Source-Technologie begeistert Sie? Bleiben Sie mit Projekten auf dem Laufenden, die einen Unterschied machen.



