Cloud-Native DevOps: Operative Herausforderungen meistern
DevOps hat sich zu einer revolutionären Bewegung für die Entwicklung einer vollwertigen Software und deren Implementierung entwickelt, wobei das gesamte System flexibel, sicher und zuverlässig bleibt. In letzter Zeit haben wir viele DevOps-Definitionen gesehen. Im Allgemeinen kann DevOps als die Gesamtheit der Grundlagen beschrieben werden, die mit Hilfe umfangreicher Tools eine kulturelle Basis zwischen den Entwicklungs- (Dev) und Operations-Teams (Ops) für die schnelle und effiziente Bereitstellung der Produkte an die Endkunden bilden.

Der Begriff wurde im Jahr 2009 von Pattrick Debois geprägt, der als "Godfather of DevOps" bezeichnet wird und der Gründer der DevOpsDays-Konferenz ist. Das Hauptanliegen einer DevOps-Kultur ist es, die Automatisierung in die Prozesse einzubringen, die zwischen den Entwicklungs- und IT-Teams stattfinden, und so den Build, das Testen und die Freigabe eines Softwareprodukts innerhalb einer Softwareentwicklungs-Kultur systematisch zu ermöglichen. Darüber hinaus trägt die Zusammenarbeit der beiden Entwicklungsbausteine dazu bei, die Silos zu beseitigen, die es seit den traditionellen Softwareentwicklungszeiten gibt. Die Zusammenführung beider Teams ist zwar etwas mühsam, aber wenn sie richtig gemacht wird, bringt sie viele bedeutende Vorteile für ein Unternehmen als Ganzes.
Da es mit dem Aufkommen von Microservices, deklarativer Infrastruktur und serverloser Architektur ständige Veränderungen in den DevOps-Praktiken gegeben hat, ist DevOps in eine neue Transformationsära eingetreten, die als "Cloud-Native DevOps" bezeichnet wird. Es kann weder als ein Tool noch als eine neue Methode bezeichnet werden, sondern eher als die Erweiterung der Reihe von Praktiken, die seit langem befolgt werden. Da die Infrastruktur in die Cloud verlagert wird und programmierbarer wird, folgen die Änderungen in der Kommunikation zwischen den Entwicklungs- und Betriebsteams, was sich auch auf die bestehende DevOps-Definition auswirkt.
Herausforderungen, die folgen
Mit der Zunahme des Umfangs der täglichen Änderungen und dem schnellen Tempo der Aufgabenerledigung arbeiten die Produktentwicklungsteams mehr als gerne in einer so schnellen Workflow-Struktur. Dies erweist sich jedoch als Wendepunkt für das Operations-Team. Eine unzählige Anzahl von Problemen und Herausforderungen folgte mit der Überlastung und der Geschwindigkeit der Arbeit, was die Fähigkeit der Operations-Teams beeinträchtigte, Dienstleistungen kompetent zu erbringen.
‘Unbegrenzte’ Interferenzen
Das Operations-Team umfasst eine Vielzahl von Aufgaben, die innerhalb eines Unternehmens stattfinden und sowohl geplante als auch ungeplante Aufgaben umfassen. Auf der einen Seite steht das Engineering, das Aufgaben wie die Produktion neuer Umgebungen, Maßnahmen zur Steigerung der Leistung und die Analyse neuer Technologien umfasst, um nur einige zu nennen. Im Gegensatz dazu treten gleichzeitig ständige Unterbrechungen wie Ereignisse im Zusammenhang mit Sicherheit, Kundenanfragen, Skalierung, Reaktion auf Vorfälle, Anfragen usw. auf, während die Operations-Teams an den zuvor genannten Aufgaben arbeiten.
Offenbar ist jede Unterbrechung, die vor dem Operations-Team auftaucht, zeitkritisch und wird vom Antragsteller ständig als dringend gekennzeichnet. Dies führt zu einer unzulässigen Beeinträchtigung der herkömmlichen operativen Aufgaben, die rechtzeitig erledigt werden müssen. Solche Unterbrechungen sind teuer. Darüber hinaus kann eine abrupte Zuweisung zur Bearbeitung der Unterbrechungen nicht erfolgen. Nur Teams mit spezifischen Fachkenntnissen, Fähigkeiten und Vorkenntnissen werden als fähig angesehen, mit den Unterbrechungen umzugehen.
Das oben genannte Szenario führt dazu, dass die Teams mit mehreren nicht so wichtigen Aufgaben belastet werden, was die Produktivität eines Unternehmens beeinträchtigt und zu Enttäuschungen und Frustrationen bei den Einzelnen führt.
Unbestimmte ‘Wartezeiten’
Wie der Name schon sagt, bezieht er sich auf die unzähligen Stunden, die mit dem Warten auf die Erledigung einer Aufgabe verbracht werden, da der Fortschritt der Aufgabe von dieser abhängig ist. Ein erheblicher Teil der Zeit wird in diesem Warte-Antwort-Warte-Zyklus verschwendet. Ähnlich wie bei den Interaktionen beeinträchtigt auch das "unbestimmte Warten" die Produktivität des Operations-Teams, was sich letztendlich auf die Effizienz des Unternehmens als Ganzes auswirkt.
Bemühungen, die ‘unendlich’ werden
Die kontinuierliche Überarbeitung der Computertechnologien im Laufe des Jahrzehnts hat zu einer großen Veränderung in der Entwicklung von Softwareanwendungen geführt. Die Systeme, die von alten Technologien zu einem völlig neuen Paradigma übergehen, werden niemals das vollständig neue Technologiemodell erwerben und die Spuren der alten Muster zurücklassen.
Der Grund dafür sind das Budget, der Risikofaktor oder eine geeignete Möglichkeit, alles von alt auf neu umzustellen. In jedem Fall liegt die umfassende Verantwortung für den Umgang damit beim Operations-Team, wenn es zu einer Verlagerung von alter zu neuer Technologie kommt, die zu einer Zunahme der Komplexität und einer Erhöhung der Legacy-Technologie-Schicht führt. Folglich bringt jeder neue Fortschritt mehr Komplexität bei der Handhabung der erhöhten Schichten der Legacy-Technologien mit sich.
Derzeit verändern DevOps und Cloud-Native-Methoden die IT-Landschaft vollständig, indem sie den gesamten IT-Workflow im Auge behalten. Der Schwerpunkt liegt auf dem Silo im Operations-Kanal. Mit DevOps und Cloud-Native bauen Unternehmen ihre Fähigkeit auf, kostengünstige und qualitativ hochwertige Produkte zu liefern.
‘Fatale’ Silos
Während die Abteilungs- und Operations-Teams in DevOps zusammenarbeiten, halten ihre Arbeitsweise, Visionen, Ziele und Verantwortlichkeiten sie immer noch zu weit voneinander entfernt, wie zwei getrennte Einheiten.
Die Entwicklung bevorzugt Geschwindigkeit, Innovation und zentralisiert die Produktivität, während Operations an Stabilität glaubt, was letztendlich den Software-Update-Prozess verlangsamt. Dies führt zu Silos im Unternehmen, die die Leistung verlangsamen.
Die Hauptfaktoren, die zu Abteilungssilos führen, sind im Folgenden aufgeführt.
- Unausgewogene Informationen: Wenn man bedenkt, dass zwei Seiten beteiligt sind, wenn eine Informationsverarbeitung aus zwei verschiedenen Perspektiven erfolgt, führt dies zu viel Verwirrung, Fehlern und vielen sich wiederholenden Arbeiten, die erledigt werden müssen.
- Operationelle Inkonsistenz: Die beteiligten Parteien führen zugewiesene Aufgaben aus und befolgen unterschiedliche operative Verfahren, um diese auszuführen. Das so entwickelte Endprodukt entspricht daher nicht den Erwartungen beider beteiligten Parteien. Es kommt zu Zeit- und Modulationsunterschieden zwischen den Teilen der Prozesse, was zu vielen anderen verschiedenen Silos führt, die letztendlich zu mehr Fehlern und sich wiederholenden Arbeiten führen.
- Kontrastierende Werkzeuge: Die verschiedenen beteiligten Parteien erhöhen, wenn sie unterschiedliche Werkzeuge verwenden oder die nicht so gut geordneten Werkzeuge, sequentiell die Nacharbeit und die Fehler innerhalb des Systems. Darüber hinaus werden auch Verzögerungen und Abweichungen in den Prozess eingeführt.
‘Unendliche’ Ticket-Warteschlangen
Die Anfragewarteschlangen erscheinen an den Grenzen der Silos und nehmen allmählich zu. Je stärker die Silos, desto länger die Anfragewarteschlangen. Der Silo-Effekt ist dominant und ermöglicht es den Teams, die Anfragen zu erfüllen, indem sie sie vom Anfragesteller trennen. Dies führt wiederum zu mehr Arbeit und mehr Fehlern. Längere Durchlaufzeiten, Variabilität, erhöhte Gemeinkosten, geringere Qualität und weniger Motivation sind die negativen Auswirkungen von Warteschlangen.
Lösung - Operations as Self-Service (OaaS)
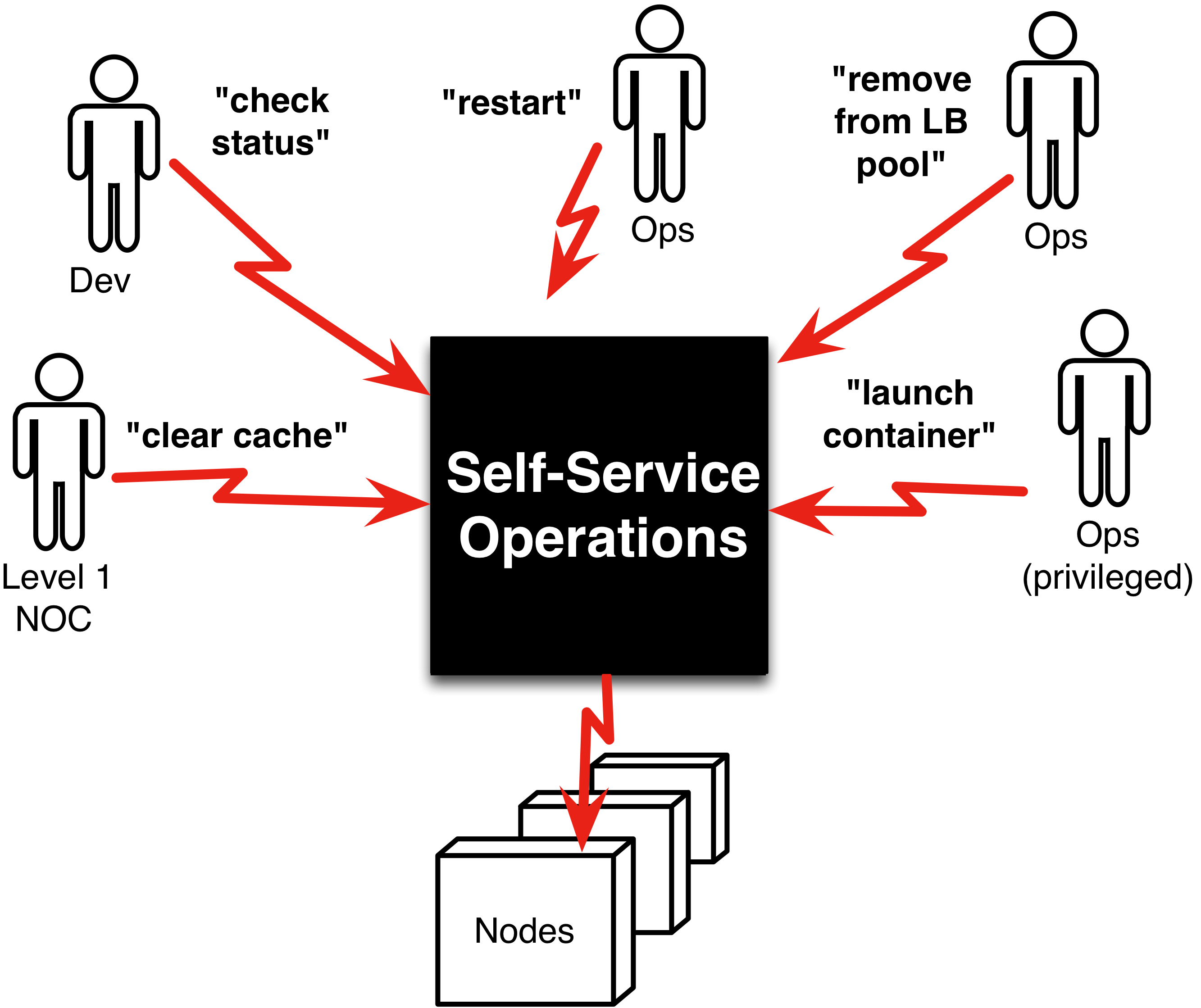
Self-Service-Operationen verbessern die Effizienz des Unternehmens, indem sie das Unternehmen auf Trab halten, um flexibler zu sein und die Dinge abzuriegeln, die bei einer bestimmten Geschwindigkeit auf Abruf sind. Eine entscheidende Technik hat sich als Segen für die Unternehmen erwiesen und die Barrieren beseitigt, die Unternehmen daran hindern, DevOps und digitale Transformationen zu erreichen.
Self-Service kann als ein rationalisierter Prozess definiert werden, bei dem die Aufgaben aus dem Betrieb in automatisierte Prozesse umgewandelt werden, die je nach Bedarf über verschiedene Kanäle wie Befehlszeile, GUI, API genutzt werden können.
Das automatisierte Verfahren umfasst die folgenden drei Elemente:
- Definieren - Definieren des automatisierten Verfahrens.
- Ausführen - Fähigkeit zur Ausführung eines automatisierten Verfahrens.
- Steuern - Steuert und lenkt die automatisierten Verfahren.
Die Rollen und Verantwortlichkeiten werden ebenfalls überprüft, z. B. wer ist für die Erstellung automatisierter Verfahren verantwortlich und wie machen sie das? , wer führt das automatisierte Verfahren aus und wie kommt es, dass sie dazu in der Lage sind? wer hat die Befehlsgewalt über das Verfahren und wie kommt es, dass sie das Sicherheits- und Compliance-Management erfolgreich durchführen?
Das Hauptziel der Grundlagen des automatisierten Verfahrens ist es, Teil einer Organisation zu sein und den Workflow zu verbessern, indem die Mühe in die richtige Richtung gelenkt wird. Die Kombination der oben genannten drei Elemente ermöglicht Self-Service-Operationen. Die Self-Service-Operationen geben der anfragenden Partei mehr Kontrolle in die Hand, so dass sie ihre Aufgaben effizienter erledigen kann, wobei die Feedbackschleifen intakt bleiben.
Ein Self-Service-Operationsmodell kann von vielen Unternehmen erfolgreich betrieben werden. Der Return on Investment basiert auf dem jeweiligen Umfeld eines Unternehmens und führt zu einer Verringerung der Reaktionszeiten, einem Rückgang von Fehlern und sich wiederholenden Arbeiten, Wartezeiten, weniger ungeplanter Arbeit usw.
Zusammenfassung
DevOps und digitale Transformationen haben sich in letzter Zeit gut entwickelt und weiten ihre Reichweite von Tag zu Tag aus. Während dies auf der einen Seite viele positive Nachrichten für die Entwicklungs- und Produktteams mit sich bringt, bringt es auf der anderen Seite viel mehr Herausforderungen für die Operations-Teams mit seinem zunehmenden Tempo und Arbeitsaufwand mit sich. Interferenzen, funktionsübergreifende Silos, endlose Ticket-Warteschlangen usw. sind einige der Herausforderungen, mit denen Unternehmen konfrontiert sind. Unternehmen sollten sich stärker darauf konzentrieren, die Warteschlangen zu begrenzen und die Silos zu minimieren. Dies kann nur mit den Zielen des Unternehmens durch Self-Service-Methoden, die als Operations as a Service (OaaS) bezeichnet werden, erreicht werden.

Newsletter abonnieren
Open-Source-Technologie begeistert Sie? Bleiben Sie mit Projekten auf dem Laufenden, die einen Unterschied machen.